 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Image Selection for Stack-Based HDR Imaging
Jun 19, 2018

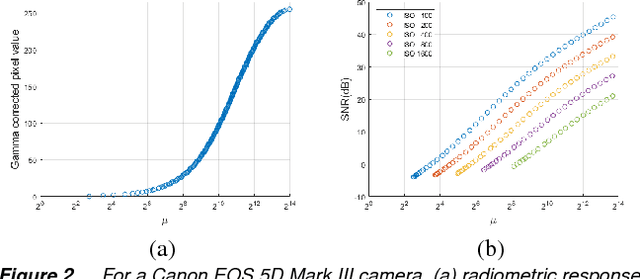
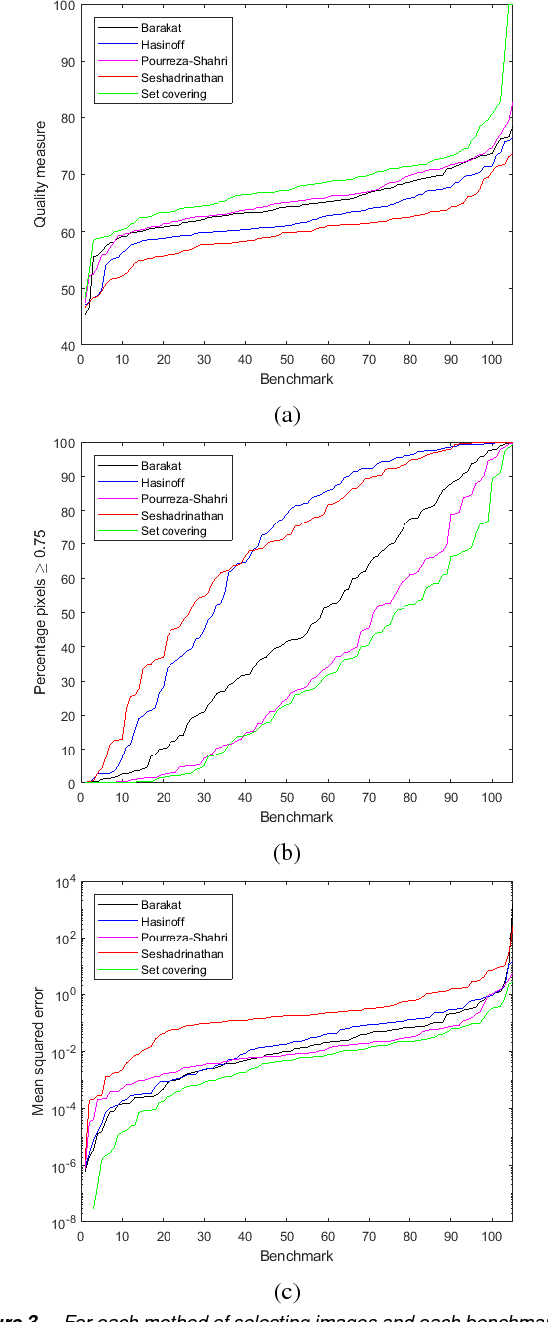
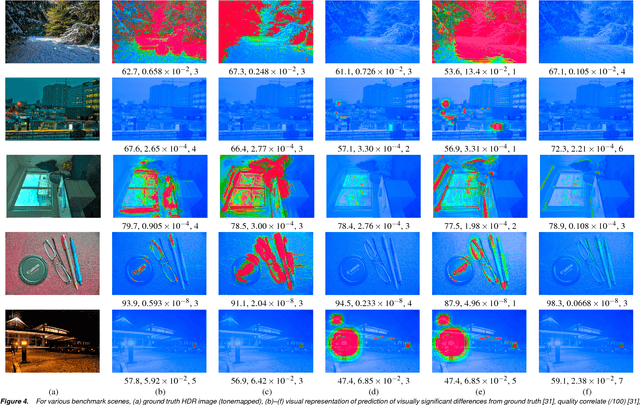
Stack-based high dynamic range (HDR) imaging is a technique for achieving a larger dynamic range in an image by combining several low dynamic range images acquired at different exposures. Minimizing the set of images to combine, while ensuring that the resulting HDR image fully captures the scene's irradiance, is important to avoid long image acquisition and post-processing times. The problem of selecting the set of images has received much attention. However, existing methods either are not fully automatic, can be slow, or can fail to fully capture more challenging scenes. In this paper, we propose a fully automatic method for selecting the set of exposures to acquire that is both fast and more accurate. We show on an extensive set of benchmark scenes that our proposed method leads to improved HDR images as measured against ground truth using the mean squared error, a pixel-based metric, and a visible difference predictor and a quality score, both perception-based metrics.
An Iterative Boundary Random Walks Algorithm for Interactive Image Segmentation
Aug 09, 2018
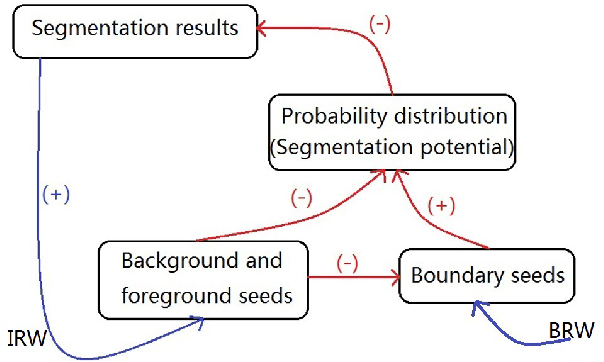
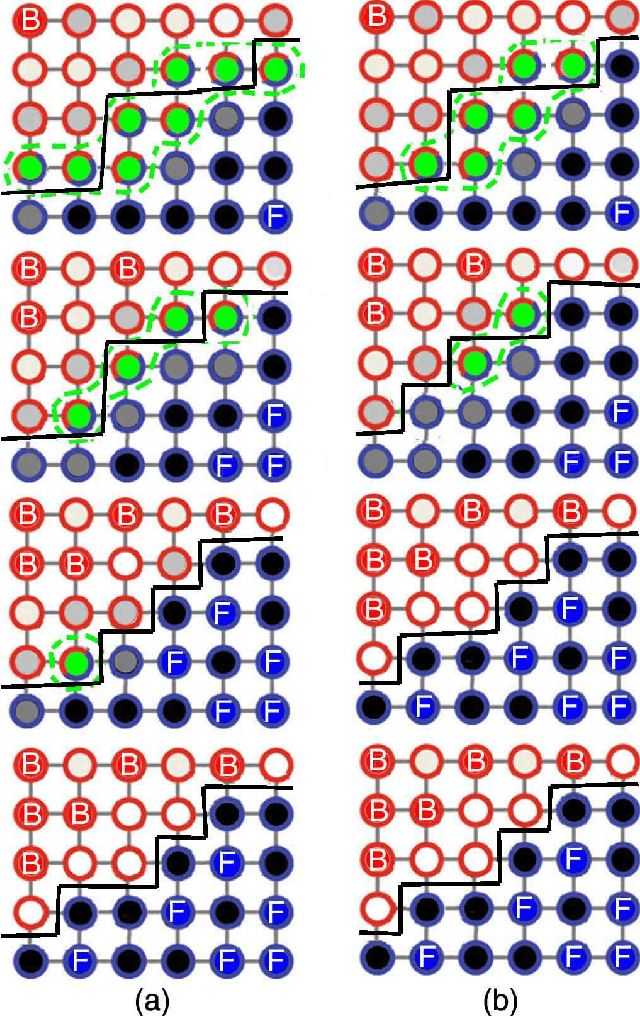
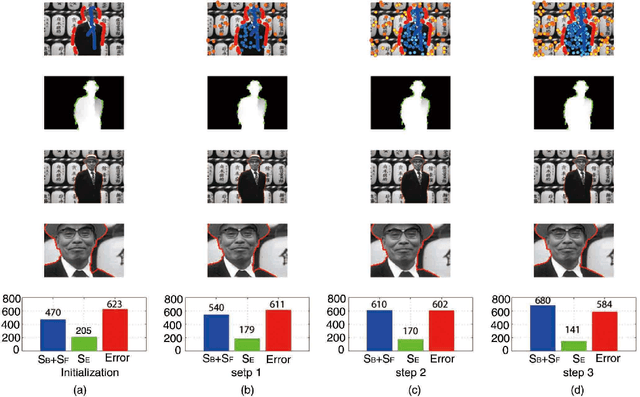
The interactive image segmentation algorithm can provide an intelligent ways to understand the intention of user input. Many interactive methods have the problem of that ask for large number of user input. To efficient produce intuitive segmentation under limited user input is important for industrial application. In this paper, we reveal a positive feedback system on image segmentation to show the pixels of self-learning. Two approaches, iterative random walks and boundary random walks, are proposed for segmentation potential, which is the key step in feedback system. Experiment results on image segmentation indicates that proposed algorithms can obtain more efficient input to random walks. And higher segmentation performance can be obtained by applying the iterative boundary random walks algorithm.
Image Based Identification of Ghanaian Timbers Using the XyloTron: Opportunities, Risks and Challenges
Dec 01, 2019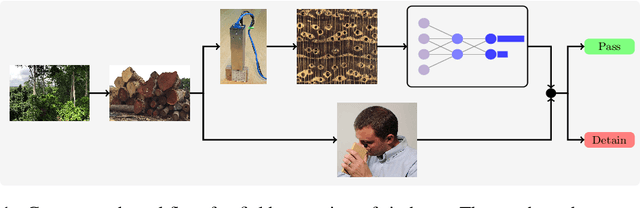
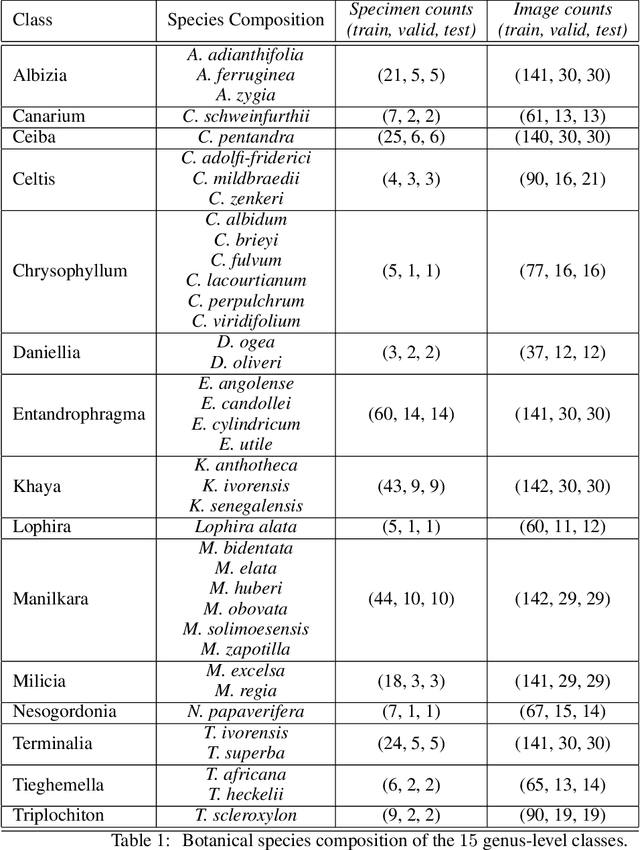

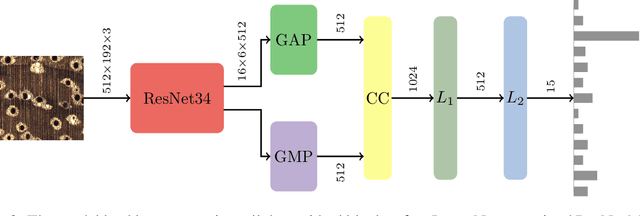
Computer vision systems for wood identification have the potential to empower both producer and consumer countries to combat illegal logging if they can be deployed effectively in the field. In this work, carried out as part of an active international partnership with the support of UNIDO, we constructed and curated a field-relevant image data set to train a classifier for wood identification of $15$ commercial Ghanaian woods using the XyloTron system. We tested model performance in the laboratory, and then collected real-world field performance data across multiple sites using multiple XyloTron devices. We present efficacies of the trained model in the laboratory and in the field, discuss practical implications and challenges of deploying machine learning wood identification models, and conclude that field testing is a necessary step - and should be considered the gold-standard - for validating computer vision wood identification systems.
Real-world Noisy Image Denoising: A New Benchmark
Apr 07, 2018



Most of previous image denoising methods focus on additive white Gaussian noise (AWGN). However,the real-world noisy image denoising problem with the advancing of the computer vision techiniques. In order to promote the study on this problem while implementing the concurrent real-world image denoising datasets, we construct a new benchmark dataset which contains comprehensive real-world noisy images of different natural scenes. These images are captured by different cameras under different camera settings. We evaluate the different denoising methods on our new dataset as well as previous datasets. Extensive experimental results demonstrate that the recently proposed methods designed specifically for realistic noise removal based on sparse or low rank theories achieve better denoising performance and are more robust than other competing methods, and the newly proposed dataset is more challenging. The constructed dataset of real photographs is publicly available at \url{https://github.com/csjunxu/PolyUDataset} for researchers to investigate new real-world image denoising methods. We will add more analysis on the noise statistics in the real photographs of our new dataset in the next version of this article.
FDMA-CDMA Mode CAOS Camera Demonstration using UV to NIR Full Spectrum
Jan 06, 2021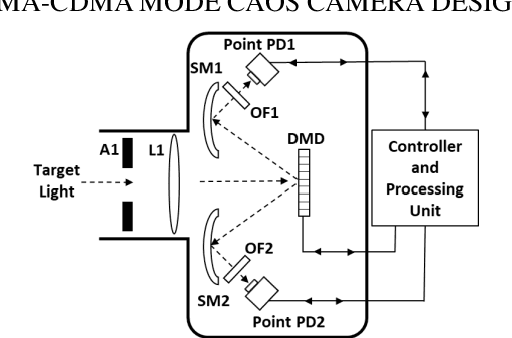
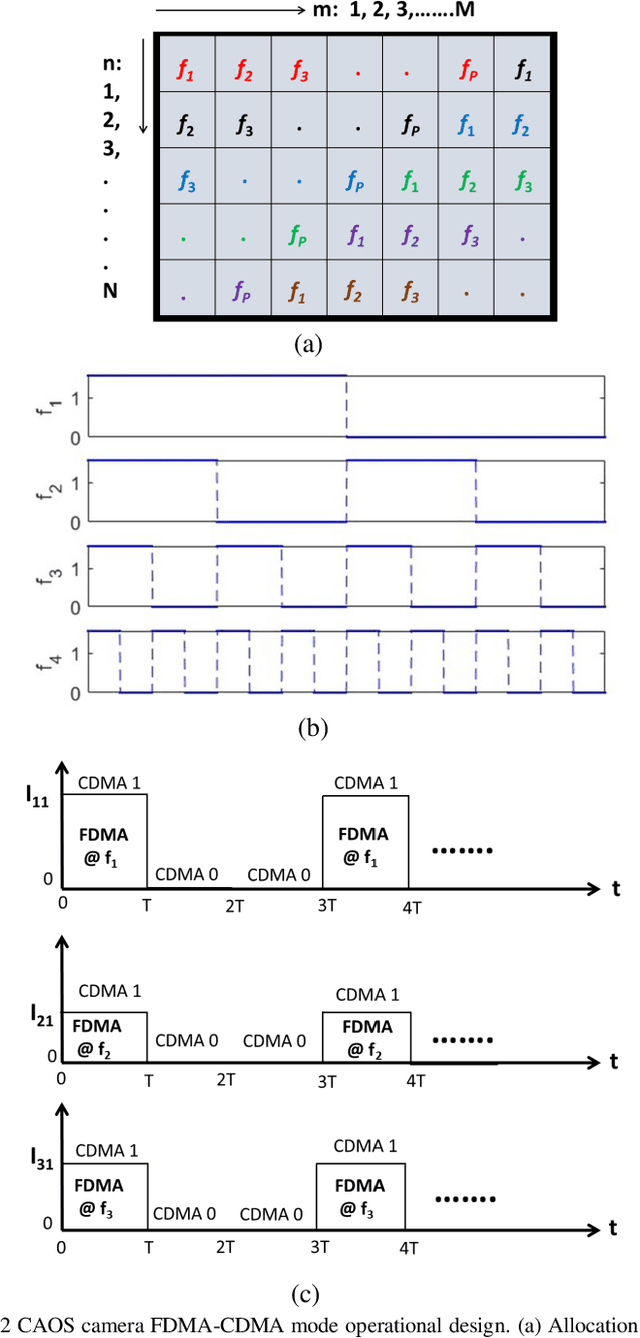
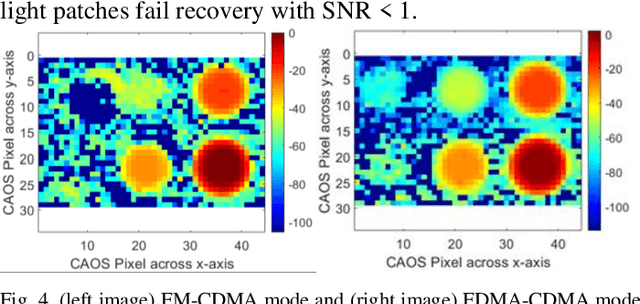
For the first time, the hybrid Frequency Division Multiple Access (FDMA) Code Division Multiple Access (CDMA) mode of the CAOS (i.e., Coded Access Optical Sensor) camera is demonstrated. The FDMA CDMA mode is a time frequency double signal encoding design for robust and faster linear High Dynamic Range (HDR) image irradiance extraction. Specifically, it simultaneously combines the strength of the FDMA-mode linear HDR Fast Fourier Transform (FFT) Digital Signal Processing (DSP) based spectrum analysis with the CDMA mode provided many simultaneous CAOS pixels high Signal to Noise Ratio (SNR) photo-detection. The FDMA CDMA mode with P FDMA channels provides a faster camera operation versus the linear HDR Frequency Modulation (FM) CDMA mode. Visible band imaging experiments using a Digital Micromirror Device (DMD) based CAOS camera demonstrate a P equal to 4 channels FDMA CDMA mode high quality image recovery of a calibrated 64 dB 6 patches HDR target versus the CDMA and FM CDMA CAOS modes that limit dynamic range and speed, respectively. Simultaneous dual image capture capability of the FDMA-CDMA mode is also demonstrated for the first time in Ultraviolet (UV) to Near Infrared (NIR) 350 to 1800 nm full spectrum using Silicon (Si) and Germanium (Ge) point photo-detectors.
On the Design of Strategic Task Recommendations for Sustainable Crowdsourcing-Based Content Moderation
Jun 04, 2021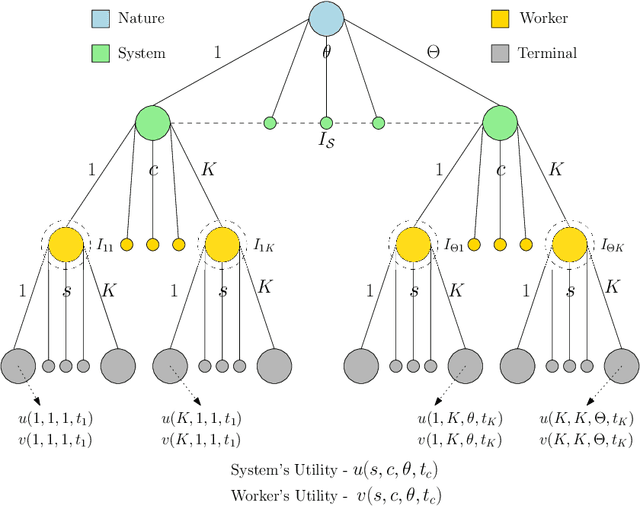
Crowdsourcing-based content moderation is a platform that hosts content moderation tasks for crowd workers to review user submissions (e.g. text, images and videos) and make decisions regarding the admissibility of the posted content, along with a gamut of other tasks such as image labeling and speech-to-text conversion. In an attempt to reduce cognitive overload at the workers and improve system efficiency, these platforms offer personalized task recommendations according to the worker's preferences. However, the current state-of-the-art recommendation systems disregard the effects on worker's mental health, especially when they are repeatedly exposed to content moderation tasks with extreme content (e.g. violent images, hate-speech). In this paper, we propose a novel, strategic recommendation system for the crowdsourcing platform that recommends jobs based on worker's mental status. Specifically, this paper models interaction between the crowdsourcing platform's recommendation system (leader) and the worker (follower) as a Bayesian Stackelberg game where the type of the follower corresponds to the worker's cognitive atrophy rate and task preferences. We discuss how rewards and costs should be designed to steer the game towards desired outcomes in terms of maximizing the platform's productivity, while simultaneously improving the working conditions of crowd workers.
Image-Based Size Analysis of Agglomerated and Partially Sintered Particles via Convolutional Neural Networks
Jul 11, 2019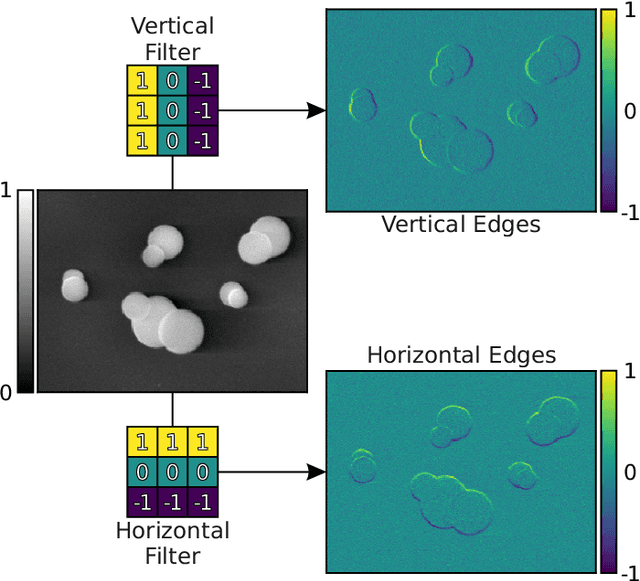
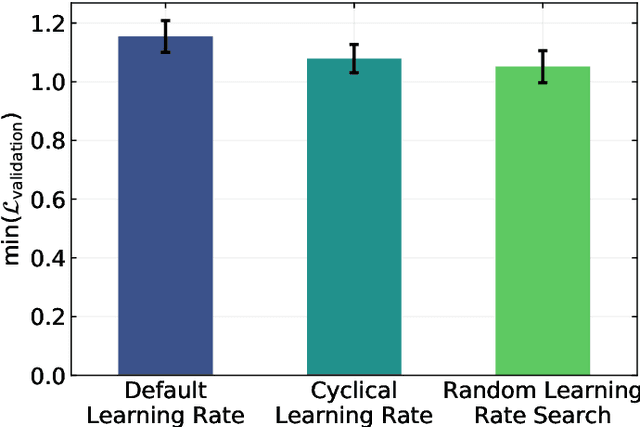
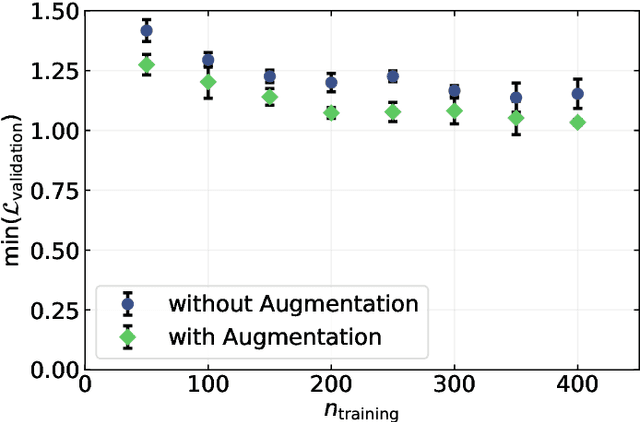
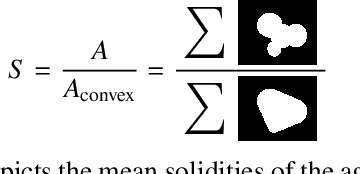
There is a high demand for fully automated methods for the analysis of particle size distributions of agglomerated, sintered or occluded primary particles. Therefore, a novel, deep learning-based, method for the pixel-perfect detection and sizing of agglomerated, aggregated or occluded primary particles was proposed and tested. As a specialty, the training of the utilized convolutional neural networks was carried out using only synthetic images, to avoid the laborious task of manual annotation and to increase the quality of the ground truth. Despite the training on synthetic images, the proposed method performs excellent on real world samples of sintered silica nanoparticles with various sintering degrees and varying image conditions. In a direct comparison, the proposed method clearly outperforms two state-of-the-art methods for automated image-based particle size analysis (Hough transformation and the ImageJ ParticleSizer plug-in), with respect to precision and speed, thereby advancing into regions of human-like performance and reliability.
A Transfer Learning based Feature-Weak-Relevant Method for Image Clustering
Aug 14, 2018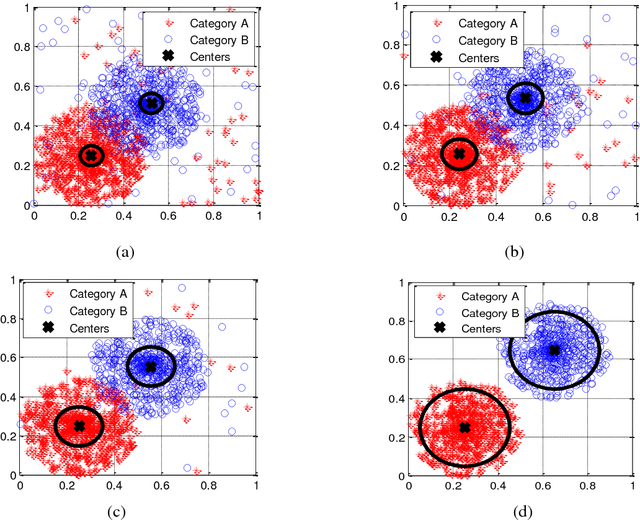
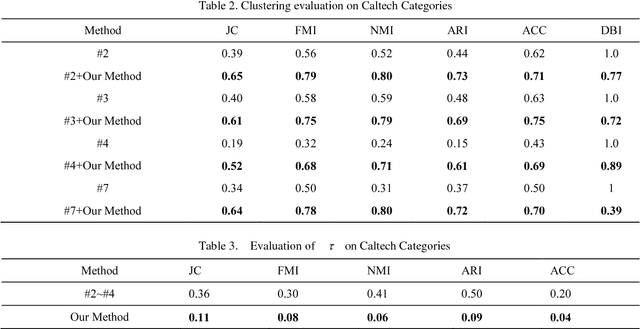
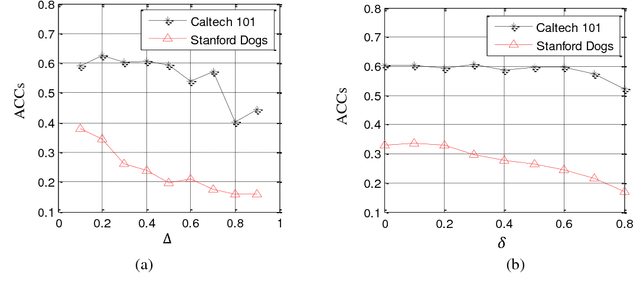
Image clustering is to group a set of images into disjoint clusters in a way that images in the same cluster are more similar to each other than to those in other clusters, which is an unsupervised or semi-supervised learning process. It is a crucial and challenging task in machine learning and computer vision. The performances of existing image clustering methods have close relations with features used for clustering, even if unsupervised coding based methods have improved the performances a lot. To reduce the effect of clustering features, we propose a feature-weak-relevant method for image clustering. The proposed method converts an unsupervised clustering process into an alternative iterative process of unsupervised learning and transfer learning. The clustering process firstly starts up from handcrafted features based image clustering to estimate an initial label for every image, and secondly use a proposed sampling strategy to choose images with reliable labels to feed a transfer-learning model to learn representative features that can be used for next round of unsupervised learning. In this manner, image clustering is iteratively optimized. What's more, the handcrafted features are used to boot up the clustering process, and just have a little effect on the final performance; therefore, the proposed method is feature-weak-relevant. Experimental results on six kinds of public available datasets show that the proposed method outperforms state of the art methods and depends less on the employed features at the same time.
Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
Jun 04, 2021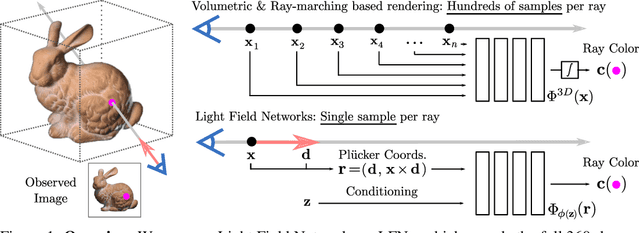

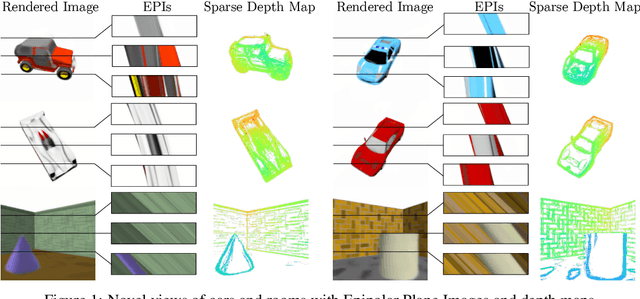
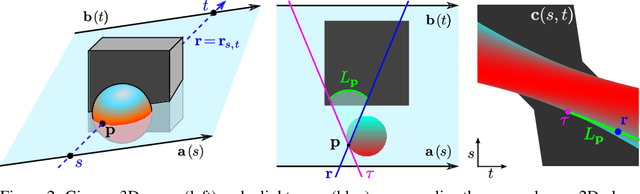
Inferring representations of 3D scenes from 2D observations is a fundamental problem of computer graphics, computer vision, and artificial intelligence. Emerging 3D-structured neural scene representations are a promising approach to 3D scene understanding. In this work, we propose a novel neural scene representation, Light Field Networks or LFNs, which represent both geometry and appearance of the underlying 3D scene in a 360-degree, four-dimensional light field parameterized via a neural implicit representation. Rendering a ray from an LFN requires only a *single* network evaluation, as opposed to hundreds of evaluations per ray for ray-marching or volumetric based renderers in 3D-structured neural scene representations. In the setting of simple scenes, we leverage meta-learning to learn a prior over LFNs that enables multi-view consistent light field reconstruction from as little as a single image observation. This results in dramatic reductions in time and memory complexity, and enables real-time rendering. The cost of storing a 360-degree light field via an LFN is two orders of magnitude lower than conventional methods such as the Lumigraph. Utilizing the analytical differentiability of neural implicit representations and a novel parameterization of light space, we further demonstrate the extraction of sparse depth maps from LFNs.
Spatial-Temporal Subset-based Digital Image Correlation: A General Framework
Dec 12, 2018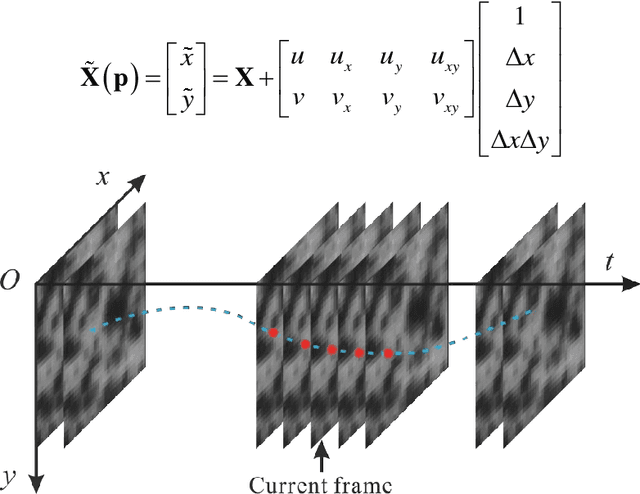
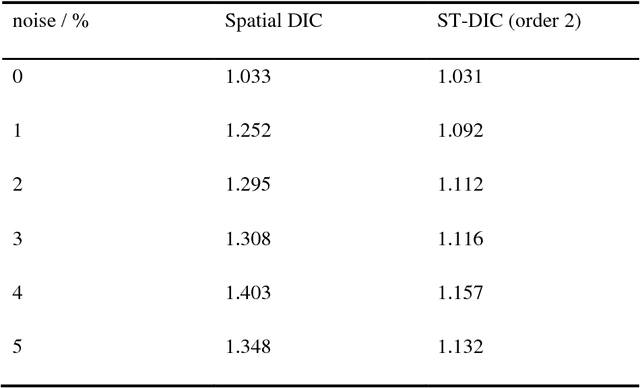
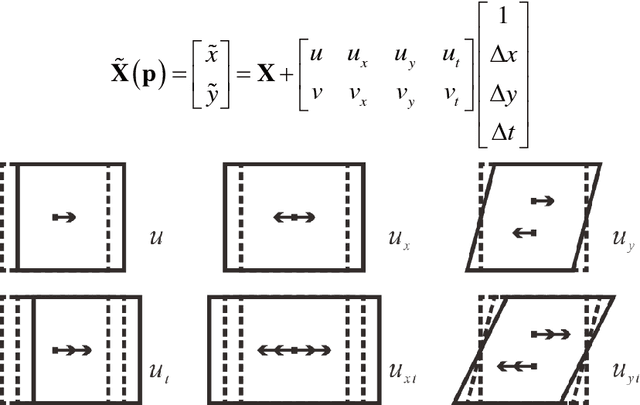
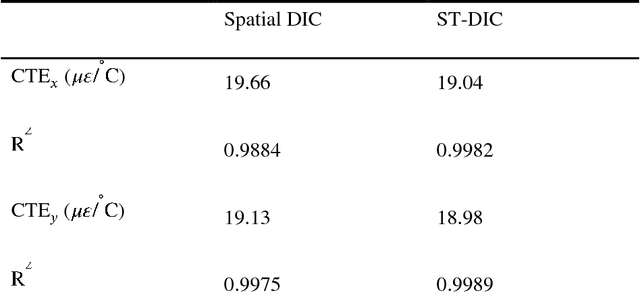
A comprehensive and systematic framework for easily extending and implementing the spatial-temporal subset-based digital image correlation (DIC) algorithm is presented. The framework decouples the three main factors (shape function, correlation criterion, and optimization algorithm) in DIC, and represents different algorithms in a uniform form. One can freely choose and combine the three factors to meet his own need, or freely add more parameters to extract analytic results. Subpixel translation and a simulated image series with different velocity characters are analyzed using different algorithms based on the proposed framework. And an application of mitigating air disturbance due to heat haze using spatial-temporal DIC (ST-DIC) is demonstrated, proving the applicability of the framework.