 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mitigating Channel-wise Noise for Single Image Super Resolution
Dec 14, 2021




In practice, images can contain different amounts of noise for different color channels, which is not acknowledged by existing super-resolution approaches. In this paper, we propose to super-resolve noisy color images by considering the color channels jointly. Noise statistics are blindly estimated from the input low-resolution image and are used to assign different weights to different color channels in the data cost. Implicit low-rank structure of visual data is enforced via nuclear norm minimization in association with adaptive weights, which is added as a regularization term to the cost. Additionally, multi-scale details of the image are added to the model through another regularization term that involves projection onto PCA basis, which is constructed using similar patches extracted across different scales of the input image. The results demonstrate the super-resolving capability of the approach in real scenarios.
Improving Computed Tomography (CT) Reconstruction via 3D Shape Induction
Aug 23, 2022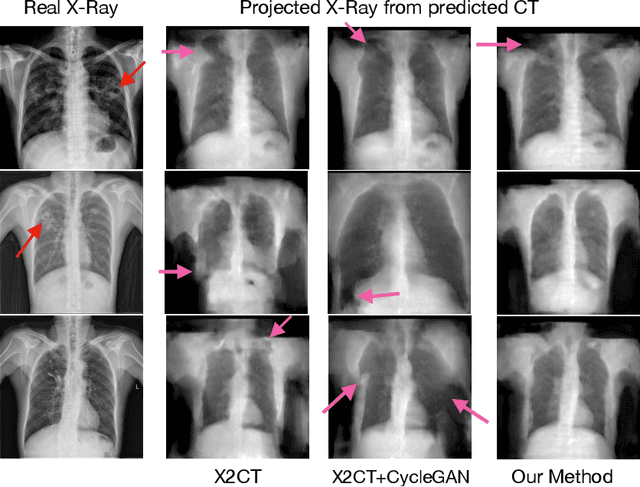

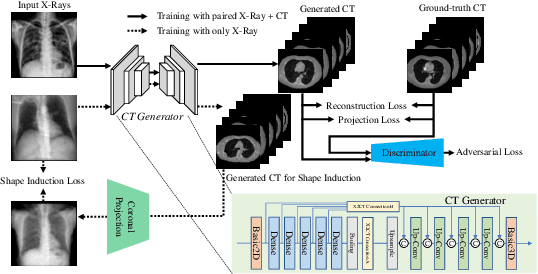

Chest computed tomography (CT) imaging adds valuable insight in the diagnosis and management of pulmonary infectious diseases, like tuberculosis (TB). However, due to the cost and resource limitations, only X-ray images may be available for initial diagnosis or follow up comparison imaging during treatment. Due to their projective nature, X-rays images may be more difficult to interpret by clinicians. The lack of publicly available paired X-ray and CT image datasets makes it challenging to train a 3D reconstruction model. In addition, Chest X-ray radiology may rely on different device modalities with varying image quality and there may be variation in underlying population disease spectrum that creates diversity in inputs. We propose shape induction, that is, learning the shape of 3D CT from X-ray without CT supervision, as a novel technique to incorporate realistic X-ray distributions during training of a reconstruction model. Our experiments demonstrate that this process improves both the perceptual quality of generated CT and the accuracy of down-stream classification of pulmonary infectious diseases.
Lightweight Monocular Depth Estimation with an Edge Guided Network
Sep 29, 2022
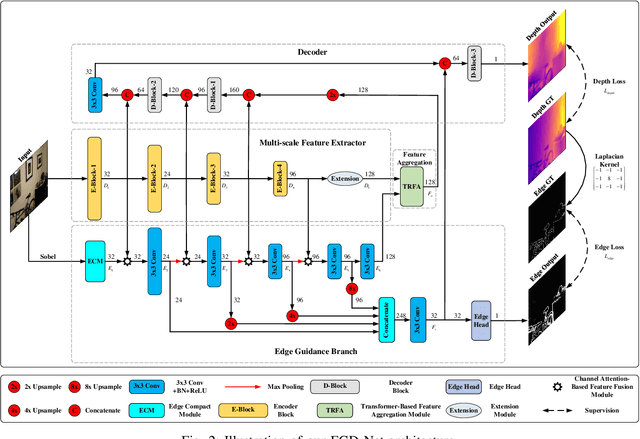
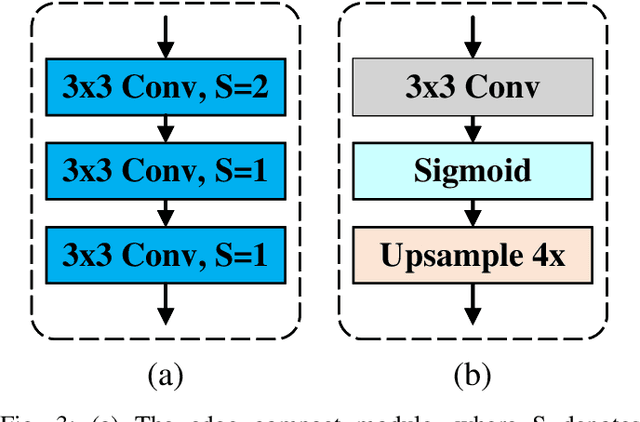
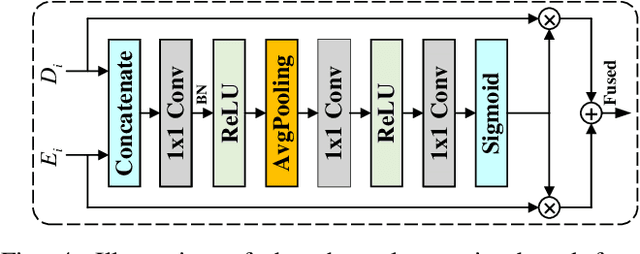
Monocular depth estimation is an important task that can be applied to many robotic applications. Existing methods focus on improving depth estimation accuracy via training increasingly deeper and wider networks, however these suffer from large computational complexity. Recent studies found that edge information are important cues for convolutional neural networks (CNNs) to estimate depth. Inspired by the above observations, we present a novel lightweight Edge Guided Depth Estimation Network (EGD-Net) in this study. In particular, we start out with a lightweight encoder-decoder architecture and embed an edge guidance branch which takes as input image gradients and multi-scale feature maps from the backbone to learn the edge attention features. In order to aggregate the context information and edge attention features, we design a transformer-based feature aggregation module (TRFA). TRFA captures the long-range dependencies between the context information and edge attention features through cross-attention mechanism. We perform extensive experiments on the NYU depth v2 dataset. Experimental results show that the proposed method runs about 96 fps on a Nvidia GTX 1080 GPU whilst achieving the state-of-the-art performance in terms of accuracy.
Deep Multimodal Guidance for Medical Image Classification
Mar 10, 2022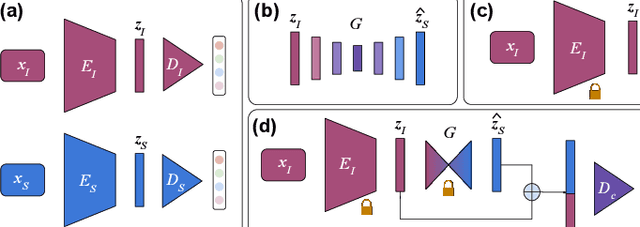
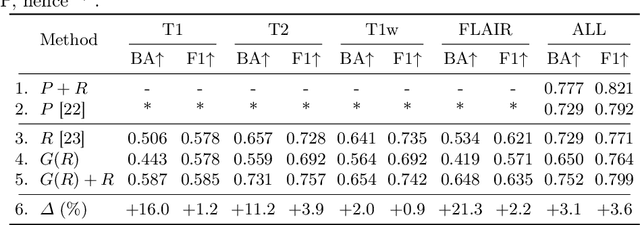
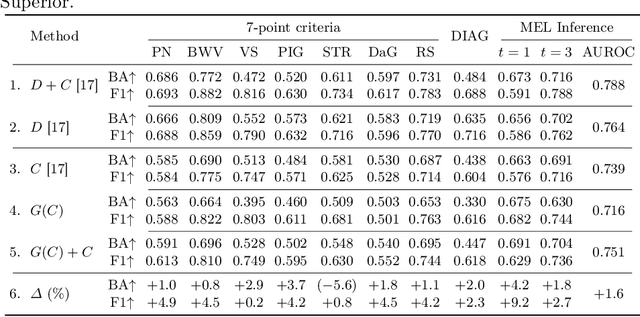
Medical imaging is a cornerstone of therapy and diagnosis in modern medicine. However, the choice of imaging modality for a particular theranostic task typically involves trade-offs between the feasibility of using a particular modality (e.g., short wait times, low cost, fast acquisition, reduced radiation/invasiveness) and the expected performance on a clinical task (e.g., diagnostic accuracy, efficacy of treatment planning and guidance). In this work, we aim to apply the knowledge learned from the less feasible but better-performing (superior) modality to guide the utilization of the more-feasible yet under-performing (inferior) modality and steer it towards improved performance. We focus on the application of deep learning for image-based diagnosis. We develop a light-weight guidance model that leverages the latent representation learned from the superior modality, when training a model that consumes only the inferior modality. We examine the advantages of our method in the context of two clinical applications: multi-task skin lesion classification from clinical and dermoscopic images and brain tumor classification from multi-sequence magnetic resonance imaging (MRI) and histopathology images. For both these scenarios we show a boost in diagnostic performance of the inferior modality without requiring the superior modality. Furthermore, in the case of brain tumor classification, our method outperforms the model trained on the superior modality while producing comparable results to the model that uses both modalities during inference.
Calibrating Segmentation Networks with Margin-based Label Smoothing
Sep 09, 2022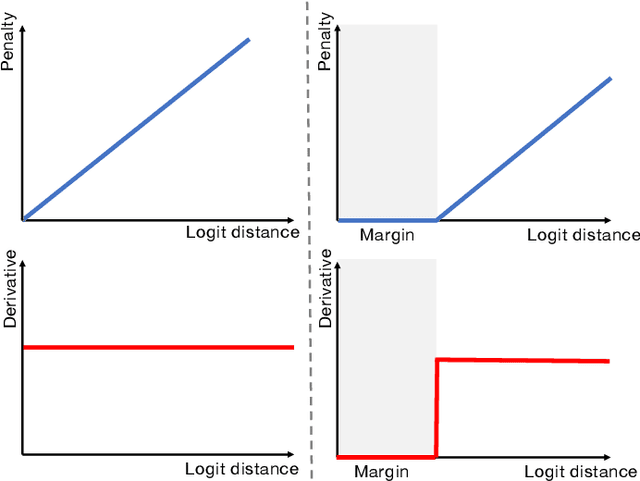
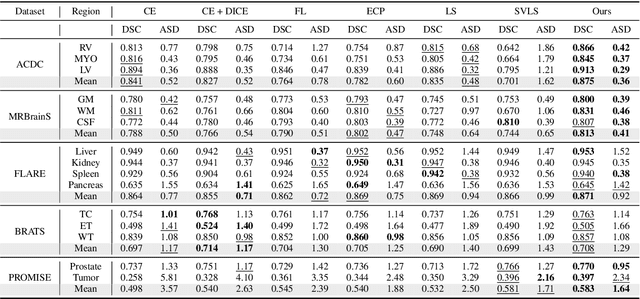

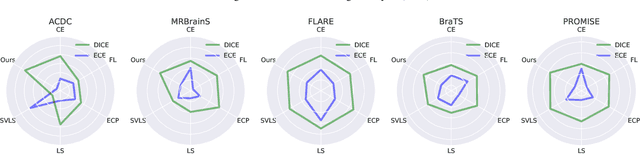
Despite the undeniable progress in visual recognition tasks fueled by deep neural networks, there exists recent evidence showing that these models are poorly calibrated, resulting in over-confident predictions. The standard practices of minimizing the cross entropy loss during training promote the predicted softmax probabilities to match the one-hot label assignments. Nevertheless, this yields a pre-softmax activation of the correct class that is significantly larger than the remaining activations, which exacerbates the miscalibration problem. Recent observations from the classification literature suggest that loss functions that embed implicit or explicit maximization of the entropy of predictions yield state-of-the-art calibration performances. Despite these findings, the impact of these losses in the relevant task of calibrating medical image segmentation networks remains unexplored. In this work, we provide a unifying constrained-optimization perspective of current state-of-the-art calibration losses. Specifically, these losses could be viewed as approximations of a linear penalty (or a Lagrangian term) imposing equality constraints on logit distances. This points to an important limitation of such underlying equality constraints, whose ensuing gradients constantly push towards a non-informative solution, which might prevent from reaching the best compromise between the discriminative performance and calibration of the model during gradient-based optimization. Following our observations, we propose a simple and flexible generalization based on inequality constraints, which imposes a controllable margin on logit distances. Comprehensive experiments on a variety of public medical image segmentation benchmarks demonstrate that our method sets novel state-of-the-art results on these tasks in terms of network calibration, whereas the discriminative performance is also improved.
Image Fusion Transformer
Jul 20, 2021
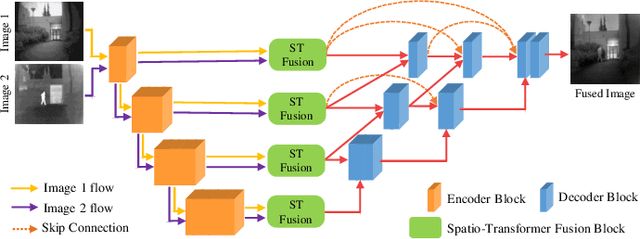
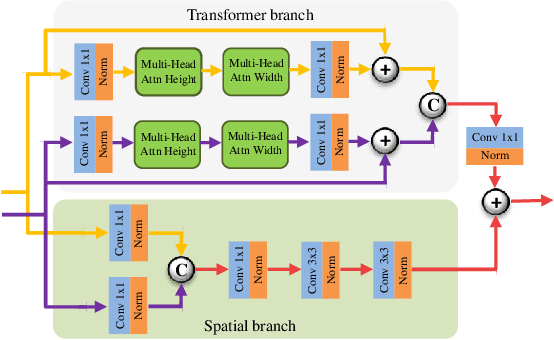
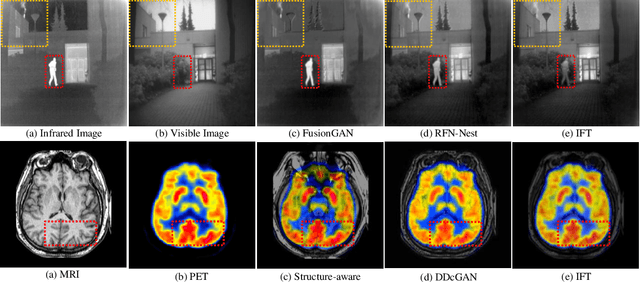
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer.
DeepSTI: Towards Tensor Reconstruction using Fewer Orientations in Susceptibility Tensor Imaging
Sep 09, 2022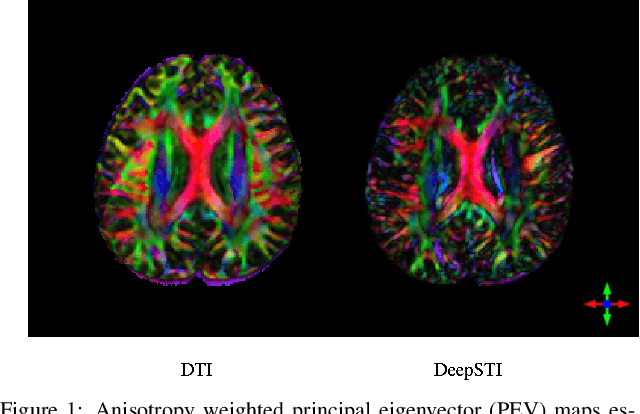
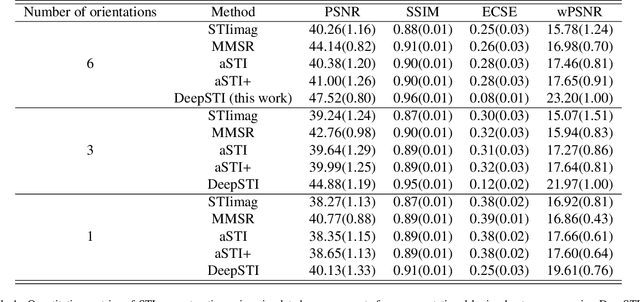
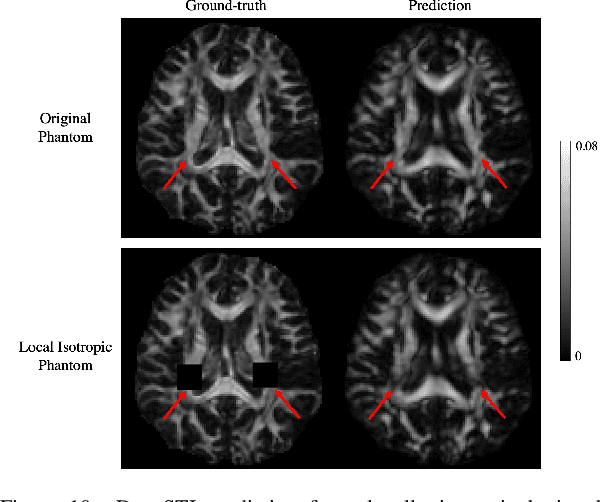
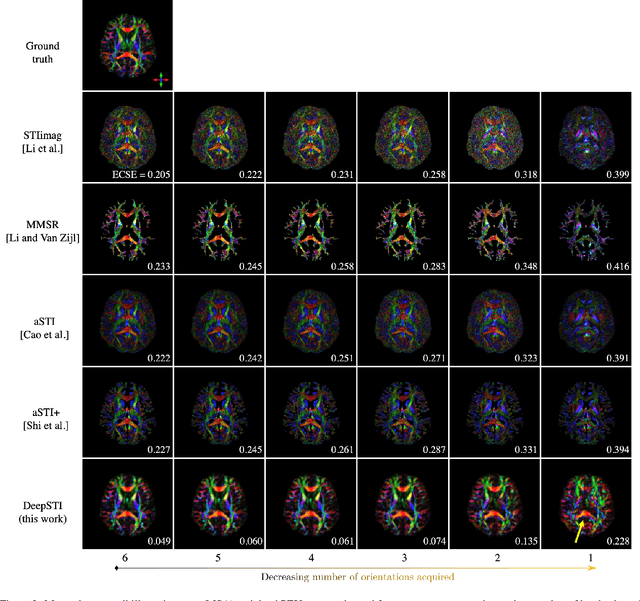
Susceptibility tensor imaging (STI) is an emerging magnetic resonance imaging technique that characterizes the anisotropic tissue magnetic susceptibility with a second-order tensor model. STI has the potential to provide information for both the reconstruction of white matter fiber pathways and detection of myelin changes in the brain at mm resolution or less, which would be of great value for understanding brain structure and function in healthy and diseased brain. However, the application of STI in vivo has been hindered by its cumbersome and time-consuming acquisition requirement of measuring susceptibility induced MR phase changes at multiple (usually more than six) head orientations. This complexity is enhanced by the limitation in head rotation angles due to physical constraints of the head coil. As a result, STI has not yet been widely applied in human studies in vivo. In this work, we tackle these issues by proposing an image reconstruction algorithm for STI that leverages data-driven priors. Our method, called DeepSTI, learns the data prior implicitly via a deep neural network that approximates the proximal operator of a regularizer function for STI. The dipole inversion problem is then solved iteratively using the learned proximal network. Experimental results using both simulation and in vivo human data demonstrate great improvement over state-of-the-art algorithms in terms of the reconstructed tensor image, principal eigenvector maps and tractography results, while allowing for tensor reconstruction with MR phase measured at much less than six different orientations. Notably, promising reconstruction results are achieved by our method from only one orientation in human in vivo, and we demonstrate a potential application of this technique for estimating lesion susceptibility anisotropy in patients with multiple sclerosis.
Modeling Image Quantization Tradeoffs for Optimal Compression
Dec 14, 2021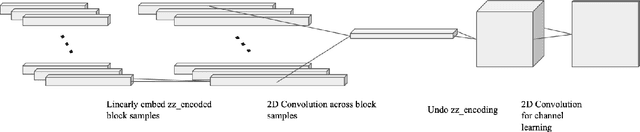
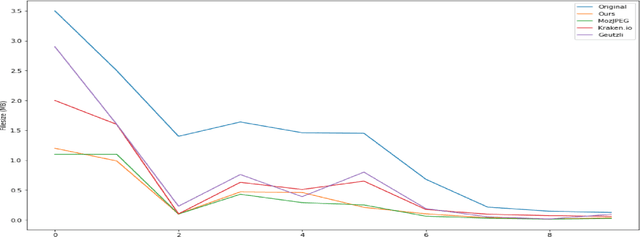
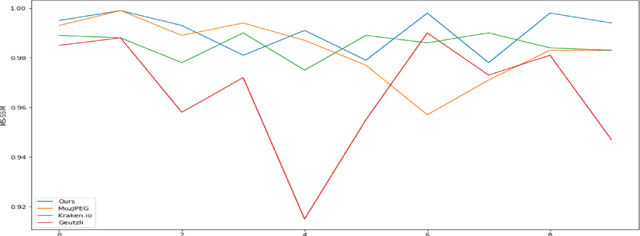
All Lossy compression algorithms employ similar compression schemes -- frequency domain transform followed by quantization and lossless encoding schemes. They target tradeoffs by quantizating high frequency data to increase compression rates which come at the cost of higher image distortion. We propose a new method of optimizing quantization tables using Deep Learning and a minimax loss function that more accurately measures the tradeoffs between rate and distortion parameters (RD) than previous methods. We design a convolutional neural network (CNN) that learns a mapping between image blocks and quantization tables in an unsupervised manner. By processing images across all channels at once, we can achieve stronger performance by also measuring tradeoffs in information loss between different channels. We initially target optimization on JPEG images but feel that this can be expanded to any lossy compressor.
U-shape Transformer for Underwater Image Enhancement
Dec 03, 2021
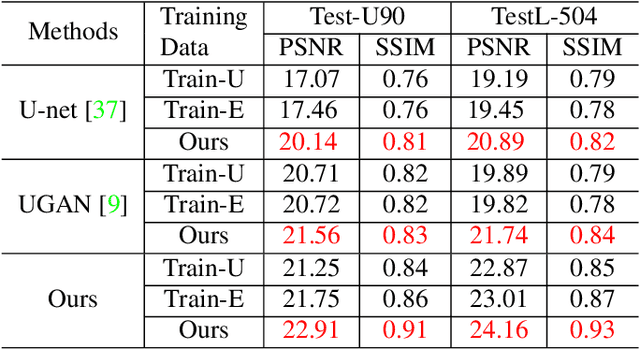
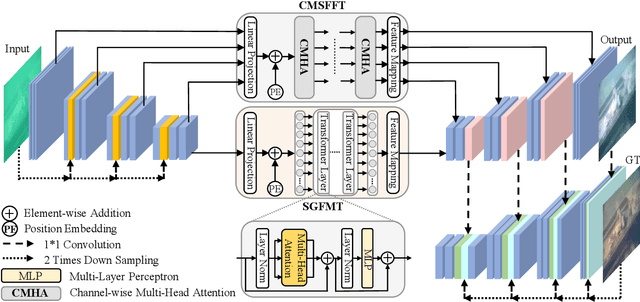
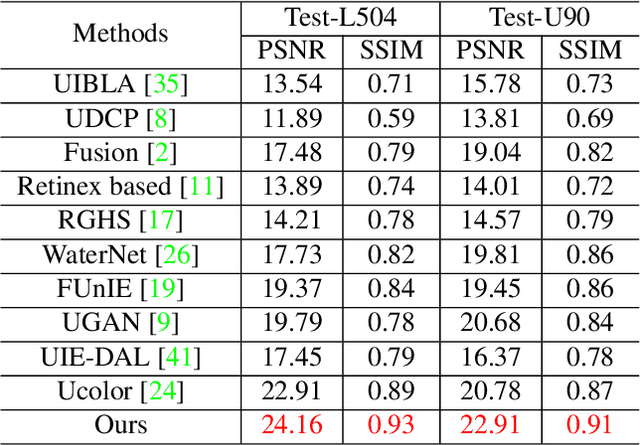
The light absorption and scattering of underwater impurities lead to poor underwater imaging quality. The existing data-driven based underwater image enhancement (UIE) techniques suffer from the lack of a large-scale dataset containing various underwater scenes and high-fidelity reference images. Besides, the inconsistent attenuation in different color channels and space areas is not fully considered for boosted enhancement. In this work, we constructed a large-scale underwater image (LSUI) dataset including 5004 image pairs, and reported an U-shape Transformer network where the transformer model is for the first time introduced to the UIE task. The U-shape Transformer is integrated with a channel-wise multi-scale feature fusion transformer (CMSFFT) module and a spatial-wise global feature modeling transformer (SGFMT) module, which reinforce the network's attention to the color channels and space areas with more serious attenuation. Meanwhile, in order to further improve the contrast and saturation, a novel loss function combining RGB, LAB and LCH color spaces is designed following the human vision principle. The extensive experiments on available datasets validate the state-of-the-art performance of the reported technique with more than 2dB superiority.
Prompt-guided Scene Generation for 3D Zero-Shot Learning
Sep 29, 2022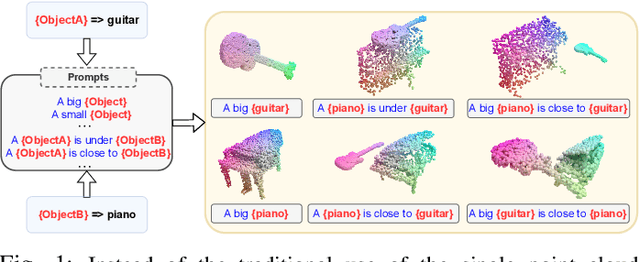
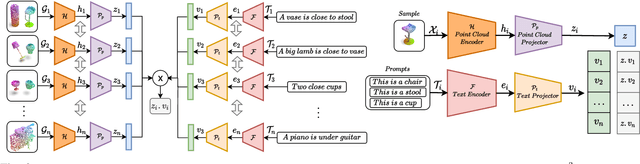
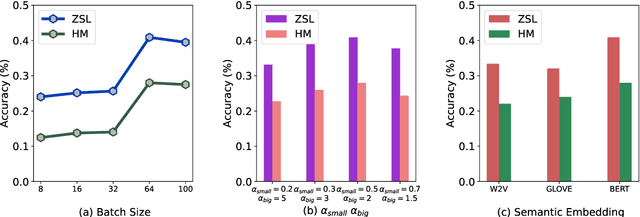

Zero-shot learning on 3D point cloud data is a related underexplored problem compared to its 2D image counterpart. 3D data brings new challenges for ZSL due to the unavailability of robust pre-trained feature extraction models. To address this problem, we propose a prompt-guided 3D scene generation and supervision method that augments 3D data to learn the network better, exploring the complex interplay of seen and unseen objects. First, we merge point clouds of two 3D models in certain ways described by a prompt. The prompt acts like the annotation describing each 3D scene. Later, we perform contrastive learning to train our proposed architecture in an end-to-end manner. We argue that 3D scenes can relate objects more efficiently than single objects because popular language models (like BERT) can achieve high performance when objects appear in a context. Our proposed prompt-guided scene generation method encapsulates data augmentation and prompt-based annotation/captioning to improve 3D ZSL performance. We have achieved state-of-the-art ZSL and generalized ZSL performance on synthetic (ModelNet40, ModelNet10) and real-scanned (ScanOjbectNN) 3D object datasets.