 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveglow
Papers and Code
Rapid Speaker Adaptation in Low Resource Text to Speech Systems using Synthetic Data and Transfer learning
Dec 02, 2023



Text-to-speech (TTS) systems are being built using end-to-end deep learning approaches. However, these systems require huge amounts of training data. We present our approach to built production quality TTS and perform speaker adaptation in extremely low resource settings. We propose a transfer learning approach using high-resource language data and synthetically generated data. We transfer the learnings from the out-domain high-resource English language. Further, we make use of out-of-the-box single-speaker TTS in the target language to generate in-domain synthetic data. We employ a three-step approach to train a high-quality single-speaker TTS system in a low-resource Indian language Hindi. We use a Tacotron2 like setup with a spectrogram prediction network and a waveglow vocoder. The Tacotron2 acoustic model is trained on English data, followed by synthetic Hindi data from the existing TTS system. Finally, the decoder of this model is fine-tuned on only 3 hours of target Hindi speaker data to enable rapid speaker adaptation. We show the importance of this dual pre-training and decoder-only fine-tuning using subjective MOS evaluation. Using transfer learning from high-resource language and synthetic corpus we present a low-cost solution to train a custom TTS model.
Code-Mixed Text to Speech Synthesis under Low-Resource Constraints
Dec 02, 2023Text-to-speech (TTS) systems are an important component in voice-based e-commerce applications. These applications include end-to-end voice assistant and customer experience (CX) voice bot. Code-mixed TTS is also relevant in these applications since the product names are commonly described in English while the surrounding text is in a regional language. In this work, we describe our approaches for production quality code-mixed Hindi-English TTS systems built for e-commerce applications. We propose a data-oriented approach by utilizing monolingual data sets in individual languages. We leverage a transliteration model to convert the Roman text into a common Devanagari script and then combine both datasets for training. We show that such single script bi-lingual training without any code-mixing works well for pure code-mixed test sets. We further present an exhaustive evaluation of single-speaker adaptation and multi-speaker training with Tacotron2 + Waveglow setup to show that the former approach works better. These approaches are also coupled with transfer learning and decoder-only fine-tuning to improve performance. We compare these approaches with the Google TTS and report a positive CMOS score of 0.02 with the proposed transfer learning approach. We also perform low-resource voice adaptation experiments to show that a new voice can be onboarded with just 3 hrs of data. This highlights the importance of our pre-trained models in resource-constrained settings. This subjective evaluation is performed on a large number of out-of-domain pure code-mixed sentences to demonstrate the high quality of the systems.
Affective social anthropomorphic intelligent system
Apr 19, 2023Human conversational styles are measured by the sense of humor, personality, and tone of voice. These characteristics have become essential for conversational intelligent virtual assistants. However, most of the state-of-the-art intelligent virtual assistants (IVAs) are failed to interpret the affective semantics of human voices. This research proposes an anthropomorphic intelligent system that can hold a proper human-like conversation with emotion and personality. A voice style transfer method is also proposed to map the attributes of a specific emotion. Initially, the frequency domain data (Mel-Spectrogram) is created by converting the temporal audio wave data, which comprises discrete patterns for audio features such as notes, pitch, rhythm, and melody. A collateral CNN-Transformer-Encoder is used to predict seven different affective states from voice. The voice is also fed parallelly to the deep-speech, an RNN model that generates the text transcription from the spectrogram. Then the transcripted text is transferred to the multi-domain conversation agent using blended skill talk, transformer-based retrieve-and-generate generation strategy, and beam-search decoding, and an appropriate textual response is generated. The system learns an invertible mapping of data to a latent space that can be manipulated and generates a Mel-spectrogram frame based on previous Mel-spectrogram frames to voice synthesize and style transfer. Finally, the waveform is generated using WaveGlow from the spectrogram. The outcomes of the studies we conducted on individual models were auspicious. Furthermore, users who interacted with the system provided positive feedback, demonstrating the system's effectiveness.
Low-Resource End-to-end Sanskrit TTS using Tacotron2, WaveGlow and Transfer Learning
Dec 07, 2022End-to-end text-to-speech (TTS) systems have been developed for European languages like English and Spanish with state-of-the-art speech quality, prosody, and naturalness. However, development of end-to-end TTS for Indian languages is lagging behind in terms of quality. The challenges involved in such a task are: 1) scarcity of quality training data; 2) low efficiency during training and inference; 3) slow convergence in the case of large vocabulary size. In our work reported in this paper, we have investigated the use of fine-tuning the English-pretrained Tacotron2 model with limited Sanskrit data to synthesize natural sounding speech in Sanskrit in low resource settings. Our experiments show encouraging results, achieving an overall MOS of 3.38 from 37 evaluators with good Sanskrit spoken knowledge. This is really a very good result, considering the fact that the speech data we have used is of duration 2.5 hours only.
Towards Parametric Speech Synthesis Using Gaussian-Markov Model of Spectral Envelope and Wavelet-Based Decomposition of F0
Aug 15, 2022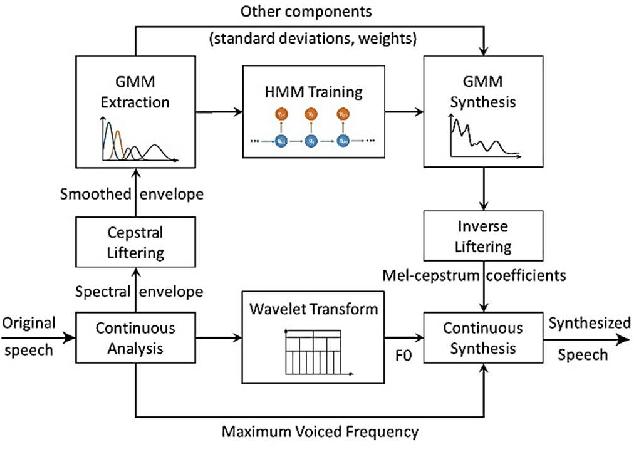
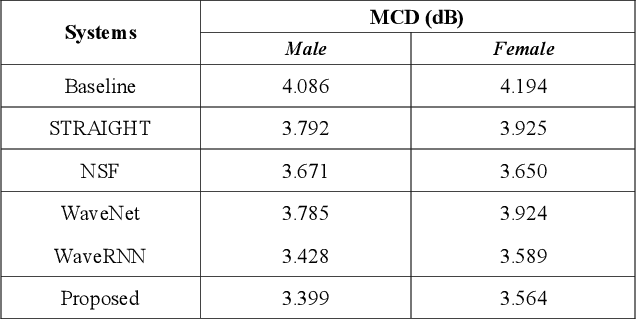
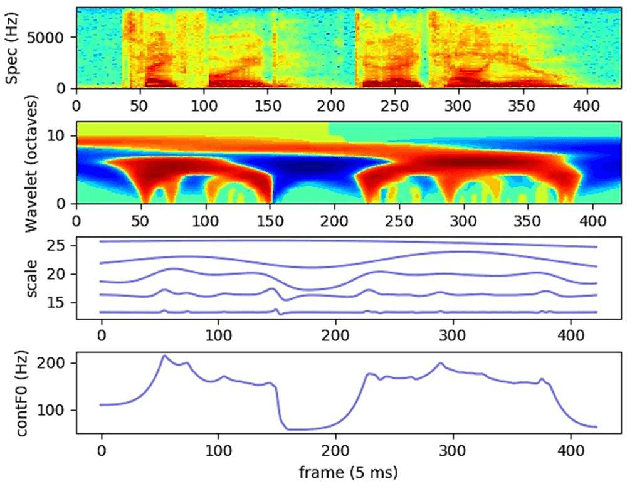
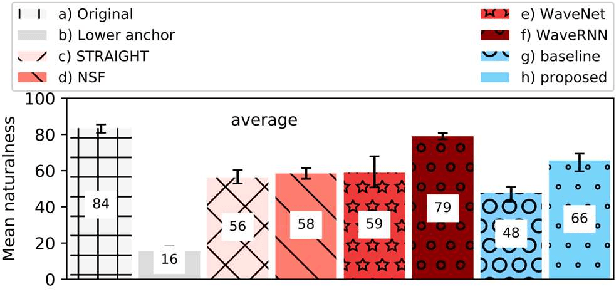
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
NatiQ: An End-to-end Text-to-Speech System for Arabic
Jun 15, 2022
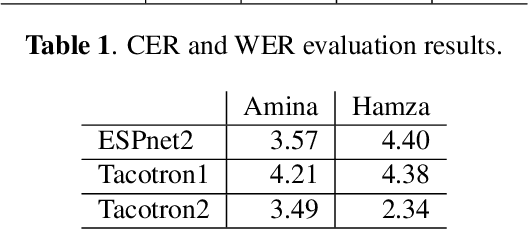
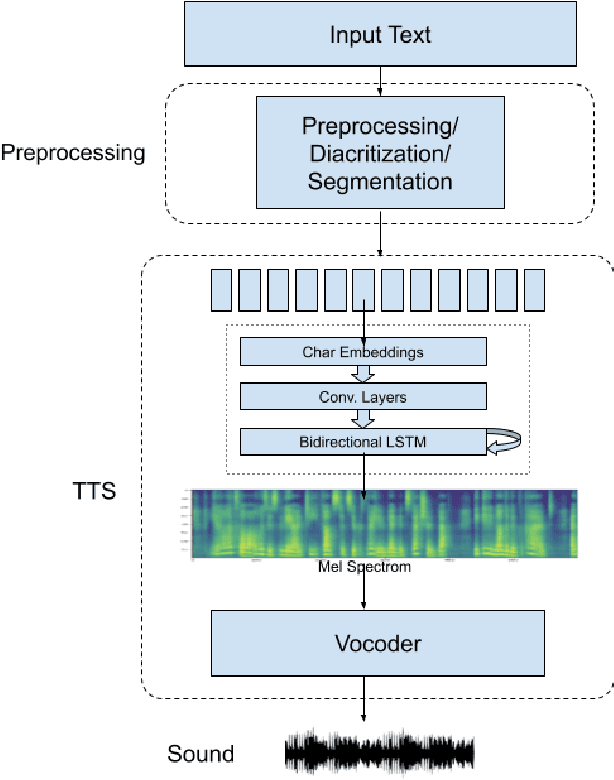
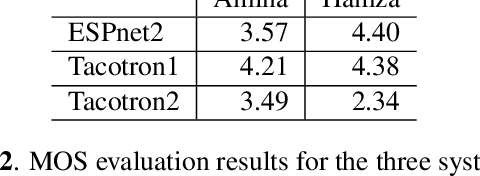
NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron-1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neutral male "Hamza"- narrating general content and news, and 2) expressive female "Amina"- narrating children story books to train our models. Our best systems achieve an average Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real-time factor favored the end-to-end architecture ESPnet. NatiQ demo is available on-line at https://tts.qcri.org
FlowVocoder: A small Footprint Neural Vocoder based Normalizing flow for Speech Synthesis
Sep 27, 2021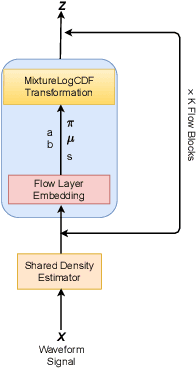

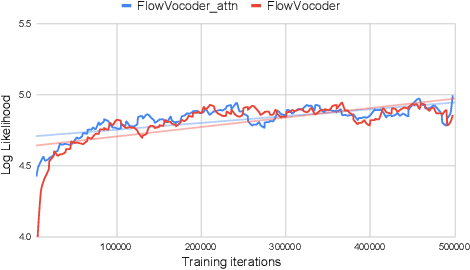
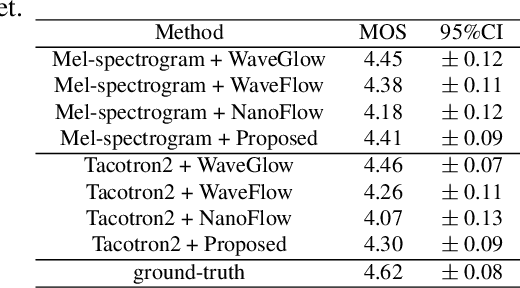
Recently, non-autoregressive neural vocoders have provided remarkable performance in generating high-fidelity speech and have been able to produce synthetic speech in real-time. However, non-autoregressive neural vocoders such as WaveGlow are far behind autoregressive neural vocoders like WaveFlow in terms of modeling audio signals due to their limitation in expressiveness. In addition, though NanoFlow is a state-of-the-art autoregressive neural vocoder that has immensely small parameters, its performance is marginally lower than WaveFlow. Therefore, in this paper, we propose a new type of autoregressive neural vocoder called FlowVocoder, which has a small memory footprint and is able to generate high-fidelity audio in real-time. Our proposed model improves the expressiveness of flow blocks by operating a mixture of Cumulative Distribution Function(CDF) for bipartite transformation. Hence, the proposed model is capable of modeling waveform signals as well as WaveFlow, while its memory footprint is much smaller thanWaveFlow. As shown in experiments, FlowVocoder achieves competitive results with baseline methods in terms of both subjective and objective evaluation, also, it is more suitable for real-time text-to-speech applications.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
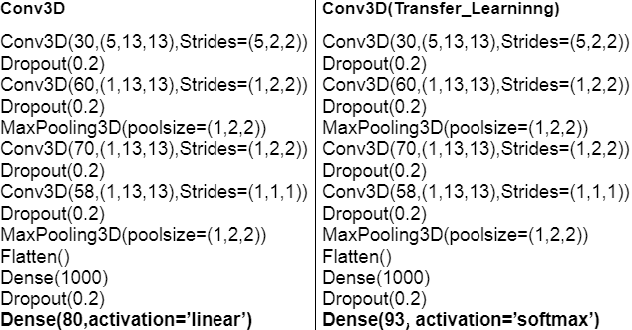
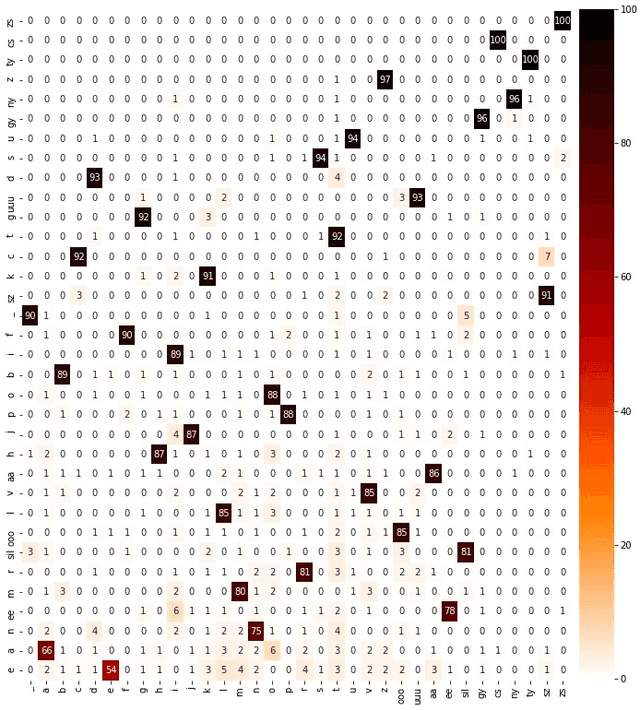
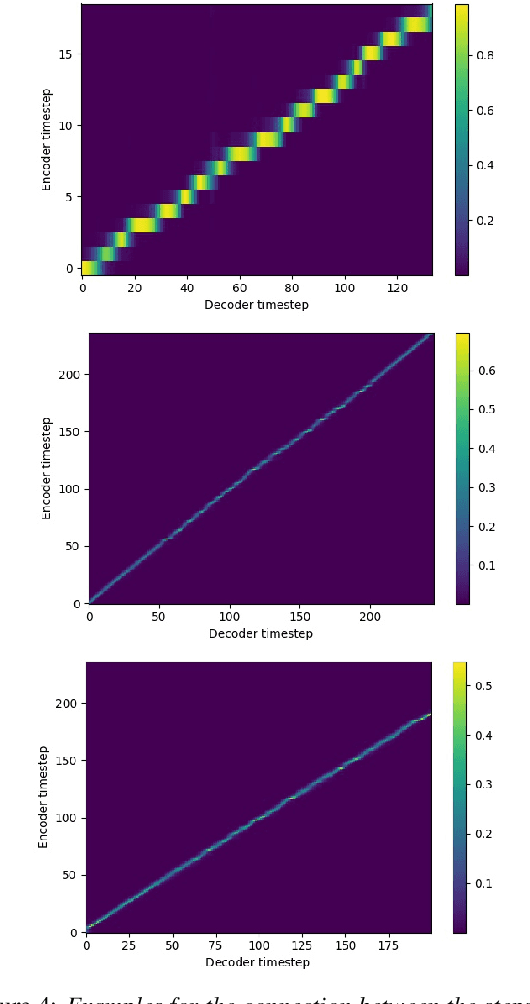
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
A Flow-Based Neural Network for Time Domain Speech Enhancement
Jun 16, 2021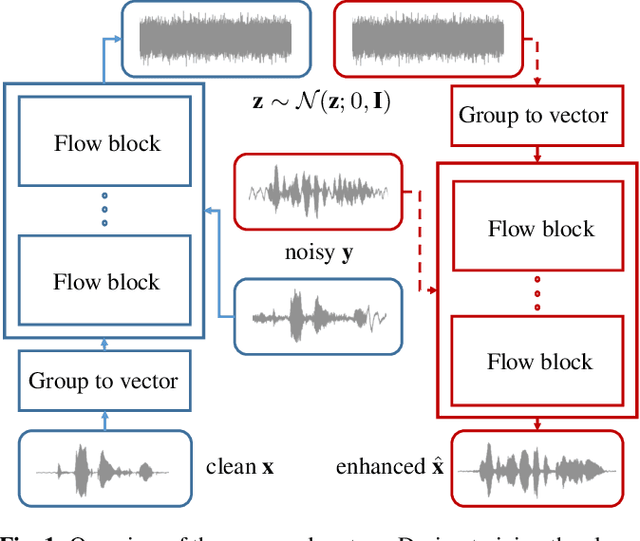
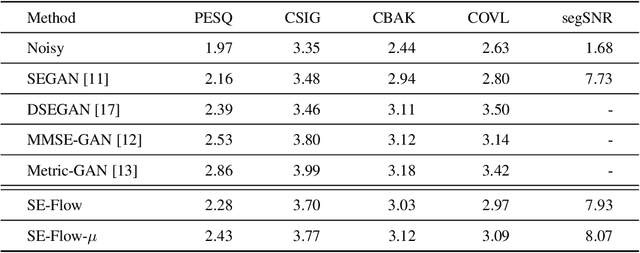
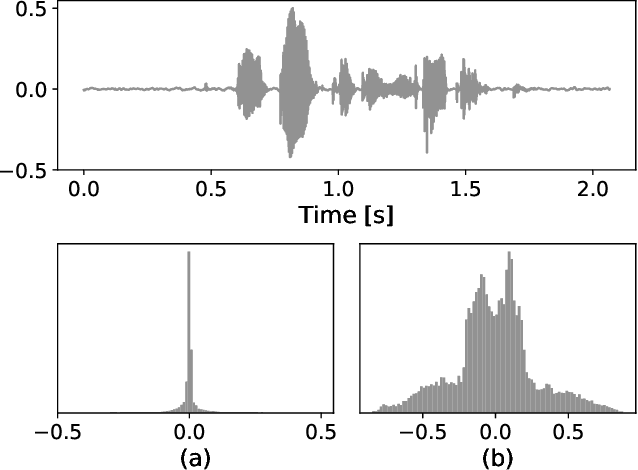
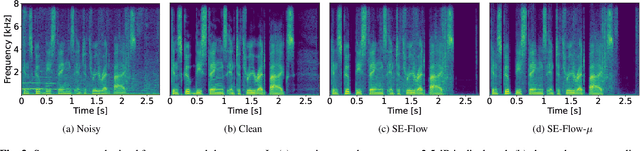
Speech enhancement involves the distinction of a target speech signal from an intrusive background. Although generative approaches using Variational Autoencoders or Generative Adversarial Networks (GANs) have increasingly been used in recent years, normalizing flow (NF) based systems are still scarse, despite their success in related fields. Thus, in this paper we propose a NF framework to directly model the enhancement process by density estimation of clean speech utterances conditioned on their noisy counterpart. The WaveGlow model from speech synthesis is adapted to enable direct enhancement of noisy utterances in time domain. In addition, we demonstrate that nonlinear input companding benefits the model performance by equalizing the distribution of input samples. Experimental evaluation on a publicly available dataset shows comparable results to current state-of-the-art GAN-based approaches, while surpassing the chosen baselines using objective evaluation metrics.
Reconstructing Speech from Real-Time Articulatory MRI Using Neural Vocoders
Apr 23, 2021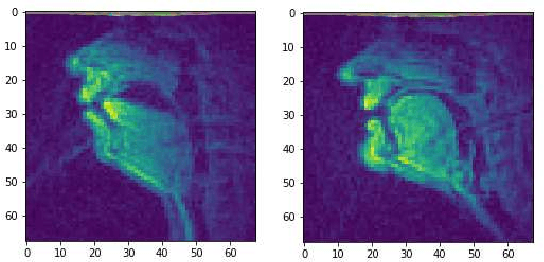
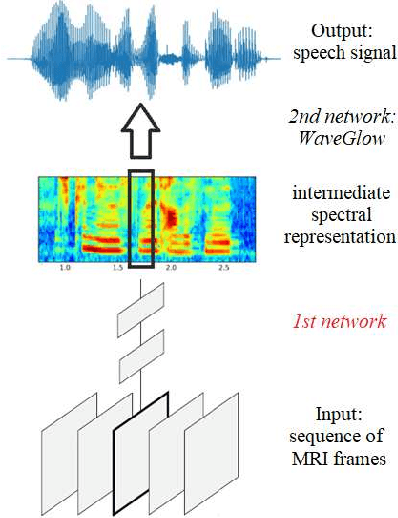
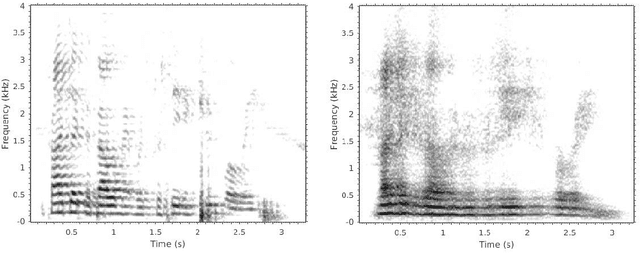

Several approaches exist for the recording of articulatory movements, such as eletromagnetic and permanent magnetic articulagraphy, ultrasound tongue imaging and surface electromyography. Although magnetic resonance imaging (MRI) is more costly than the above approaches, the recent developments in this area now allow the recording of real-time MRI videos of the articulators with an acceptable resolution. Here, we experiment with the reconstruction of the speech signal from a real-time MRI recording using deep neural networks. Instead of estimating speech directly, our networks are trained to output a spectral vector, from which we reconstruct the speech signal using the WaveGlow neural vocoder. We compare the performance of three deep neural architectures for the estimation task, combining convolutional (CNN) and recurrence-based (LSTM) neural layers. Besides the mean absolute error (MAE) of our networks, we also evaluate our models by comparing the speech signals obtained using several objective speech quality metrics like the mean cepstral distortion (MCD), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ) and Signal-to-Distortion Ratio (SDR). The results indicate that our approach can successfully reconstruct the gross spectral shape, but more improvements are needed to reproduce the fine spectral details.