 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrocr
Papers and Code
Adapting TrOCR for Printed Tigrinya Text Recognition: Word-Aware Loss Weighting for Cross-Script Transfer Learning
Apr 22, 2026Transformer-based OCR models have shown strong performance on Latin and CJK scripts, but their application to African syllabic writing systems remains limited. We present the first adaptation of TrOCR for printed Tigrinya using the Ge'ez script. Starting from a pre-trained model, we extend the byte-level BPE tokenizer to cover 230 Ge'ez characters and introduce Word-Aware Loss Weighting to resolve systematic word-boundary failures that arise when applying Latin-centric BPE conventions to a new script. The unmodified model produces no usable output on Ge'ez text. After adaptation, the TrOCR-Printed variant achieves 0.22% Character Error Rate and 97.20% exact match accuracy on a held-out test set of 5,000 synthetic images from the GLOCR dataset. An ablation study confirms that Word-Aware Loss Weighting is the critical component, reducing CER by two orders of magnitude compared to vocabulary extension alone. The full pipeline trains in under three hours on a single 8 GB consumer GPU. All code, model weights, and evaluation scripts are publicly released.
A Benchmark of State-Space Models vs. Transformers and BiLSTM-based Models for Historical Newspaper OCR
Apr 01, 2026End-to-end OCR for historical newspapers remains challenging, as models must handle long text sequences, degraded print quality, and complex layouts. While Transformer-based recognizers dominate current research, their quadratic complexity limits efficient paragraph-level transcription and large-scale deployment. We investigate linear-time State-Space Models (SSMs), specifically Mamba, as a scalable alternative to Transformer-based sequence modeling for OCR. We present to our knowledge, the first OCR architecture based on SSMs, combining a CNN visual encoder with bi-directional and autoregressive Mamba sequence modeling, and conduct a large-scale benchmark comparing SSMs with Transformer- and BiLSTM-based recognizers. Multiple decoding strategies (CTC, autoregressive, and non-autoregressive) are evaluated under identical training conditions alongside strong neural baselines (VAN, DAN, DANIEL) and widely used off-the-shelf OCR engines (PERO-OCR, Tesseract OCR, TrOCR, Gemini). Experiments on historical newspapers from the Bibliothèque nationale du Luxembourg, with newly released >99% verified gold-standard annotations, and cross-dataset tests on Fraktur and Antiqua lines, show that all neural models achieve low error rates (~2% CER), making computational efficiency the main differentiator. Mamba-based models maintain competitive accuracy while halving inference time and exhibiting superior memory scaling (1.26x vs 2.30x growth at 1000 chars), reaching 6.07% CER at the severely degraded paragraph level compared to 5.24% for DAN, while remaining 2.05x faster. We release code, trained models, and standardized evaluation protocols to enable reproducible research and guide practitioners in large-scale cultural heritage OCR.
Error Patterns in Historical OCR: A Comparative Analysis of TrOCR and a Vision-Language Model
Feb 16, 2026Optical Character Recognition (OCR) of eighteenth-century printed texts remains challenging due to degraded print quality, archaic glyphs, and non-standardized orthography. Although transformer-based OCR systems and Vision-Language Models (VLMs) achieve strong aggregate accuracy, metrics such as Character Error Rate (CER) and Word Error Rate (WER) provide limited insight into their reliability for scholarly use. We compare a dedicated OCR transformer (TrOCR) and a general-purpose Vision-Language Model (Qwen) on line-level historical English texts using length-weighted accuracy metrics and hypothesis driven error analysis. While Qwen achieves lower CER/WER and greater robustness to degraded input, it exhibits selective linguistic regularization and orthographic normalization that may silently alter historically meaningful forms. TrOCR preserves orthographic fidelity more consistently but is more prone to cascading error propagation. Our findings show that architectural inductive biases shape OCR error structure in systematic ways. Models with similar aggregate accuracy can differ substantially in error locality, detectability, and downstream scholarly risk, underscoring the need for architecture-aware evaluation in historical digitization workflows.
synthocr-gen: A synthetic ocr dataset generator for low-resource languages- breaking the data barrier
Jan 22, 2026Optical Character Recognition (OCR) for low-resource languages remains a significant challenge due to the scarcity of large-scale annotated training datasets. Languages such as Kashmiri, with approximately 7 million speakers and a complex Perso-Arabic script featuring unique diacritical marks, currently lack support in major OCR systems including Tesseract, TrOCR, and PaddleOCR. Manual dataset creation for such languages is prohibitively expensive, time-consuming, and error-prone, often requiring word by word transcription of printed or handwritten text. We present SynthOCR-Gen, an open-source synthetic OCR dataset generator specifically designed for low-resource languages. Our tool addresses the fundamental bottleneck in OCR development by transforming digital Unicode text corpora into ready-to-use training datasets. The system implements a comprehensive pipeline encompassing text segmentation (character, word, n-gram, sentence, and line levels), Unicode normalization with script purity enforcement, multi-font rendering with configurable distribution, and 25+ data augmentation techniques simulating real-world document degradations including rotation, blur, noise, and scanner artifacts. We demonstrate the efficacy of our approach by generating a 600,000-sample word-segmented Kashmiri OCR dataset, which we release publicly on HuggingFace. This work provides a practical pathway for bringing low-resource languages into the era of vision-language AI models, and the tool is openly available for researchers and practitioners working with underserved writing systems worldwide.
600k-ks-ocr: a large-scale synthetic dataset for optical character recognition in kashmiri script
Jan 03, 2026This technical report presents the 600K-KS-OCR Dataset, a large-scale synthetic corpus comprising approximately 602,000 word-level segmented images designed for training and evaluating optical character recognition systems targeting Kashmiri script. The dataset addresses a critical resource gap for Kashmiri, an endangered Dardic language utilizing a modified Perso-Arabic writing system spoken by approximately seven million people. Each image is rendered at 256x64 pixels with corresponding ground-truth transcriptions provided in multiple formats compatible with CRNN, TrOCR, and generalpurpose machine learning pipelines. The generation methodology incorporates three traditional Kashmiri typefaces, comprehensive data augmentation simulating real-world document degradation, and diverse background textures to enhance model robustness. The dataset is distributed across ten partitioned archives totaling approximately 10.6 GB and is released under the CC-BY-4.0 license to facilitate research in low-resource language optical character recognition.
Psychological stress during Examination and its estimation by handwriting in answer script
Nov 08, 2025This research explores the fusion of graphology and artificial intelligence to quantify psychological stress levels in students by analyzing their handwritten examination scripts. By leveraging Optical Character Recognition and transformer based sentiment analysis models, we present a data driven approach that transcends traditional grading systems, offering deeper insights into cognitive and emotional states during examinations. The system integrates high resolution image processing, TrOCR, and sentiment entropy fusion using RoBERTa based models to generate a numerical Stress Index. Our method achieves robustness through a five model voting mechanism and unsupervised anomaly detection, making it an innovative framework in academic forensics.
Improving OCR for Historical Texts of Multiple Languages
Aug 14, 2025This paper presents our methodology and findings from three tasks across Optical Character Recognition (OCR) and Document Layout Analysis using advanced deep learning techniques. First, for the historical Hebrew fragments of the Dead Sea Scrolls, we enhanced our dataset through extensive data augmentation and employed the Kraken and TrOCR models to improve character recognition. In our analysis of 16th to 18th-century meeting resolutions task, we utilized a Convolutional Recurrent Neural Network (CRNN) that integrated DeepLabV3+ for semantic segmentation with a Bidirectional LSTM, incorporating confidence-based pseudolabeling to refine our model. Finally, for modern English handwriting recognition task, we applied a CRNN with a ResNet34 encoder, trained using the Connectionist Temporal Classification (CTC) loss function to effectively capture sequential dependencies. This report offers valuable insights and suggests potential directions for future research.
A document processing pipeline for the construction of a dataset for topic modeling based on the judgments of the Italian Supreme Court
May 13, 2025Topic modeling in Italian legal research is hindered by the lack of public datasets, limiting the analysis of legal themes in Supreme Court judgments. To address this, we developed a document processing pipeline that produces an anonymized dataset optimized for topic modeling. The pipeline integrates document layout analysis (YOLOv8x), optical character recognition, and text anonymization. The DLA module achieved a mAP@50 of 0.964 and a mAP@50-95 of 0.800. The OCR detector reached a mAP@50-95 of 0.9022, and the text recognizer (TrOCR) obtained a character error rate of 0.0047 and a word error rate of 0.0248. Compared to OCR-only methods, our dataset improved topic modeling with a diversity score of 0.6198 and a coherence score of 0.6638. We applied BERTopic to extract topics and used large language models to generate labels and summaries. Outputs were evaluated against domain expert interpretations. Claude Sonnet 3.7 achieved a BERTScore F1 of 0.8119 for labeling and 0.9130 for summarization.
Early evidence of how LLMs outperform traditional systems on OCR/HTR tasks for historical records
Jan 20, 2025



We explore the ability of two LLMs -- GPT-4o and Claude Sonnet 3.5 -- to transcribe historical handwritten documents in a tabular format and compare their performance to traditional OCR/HTR systems: EasyOCR, Keras, Pytesseract, and TrOCR. Considering the tabular form of the data, two types of experiments are executed: one where the images are split line by line and the other where the entire scan is used as input. Based on CER and BLEU, we demonstrate that LLMs outperform the conventional OCR/HTR methods. Moreover, we also compare the evaluated CER and BLEU scores to human evaluations to better judge the outputs of whole-scan experiments and understand influential factors for CER and BLEU. Combining judgments from all the evaluation metrics, we conclude that two-shot GPT-4o for line-by-line images and two-shot Claude Sonnet 3.5 for whole-scan images yield the transcriptions of the historical records most similar to the ground truth.
Comparative analysis of optical character recognition methods for Sámi texts from the National Library of Norway
Jan 13, 2025
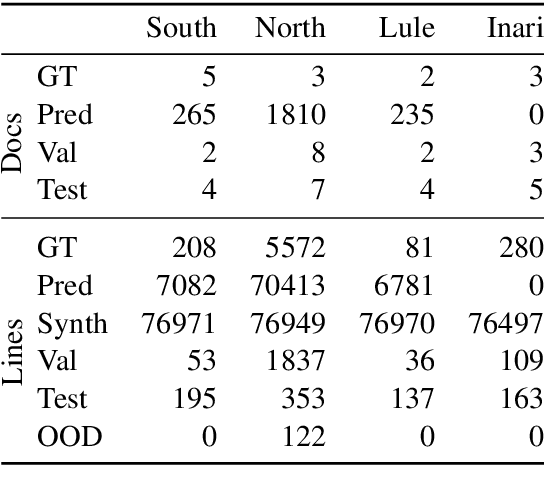
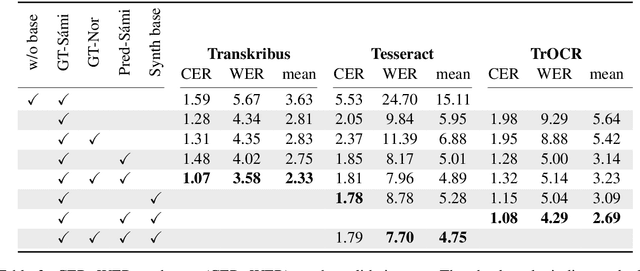
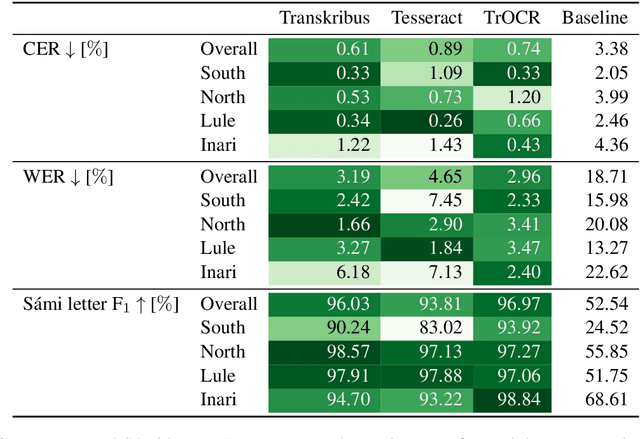
Optical Character Recognition (OCR) is crucial to the National Library of Norway's (NLN) digitisation process as it converts scanned documents into machine-readable text. However, for the S\'ami documents in NLN's collection, the OCR accuracy is insufficient. Given that OCR quality affects downstream processes, evaluating and improving OCR for text written in S\'ami languages is necessary to make these resources accessible. To address this need, this work fine-tunes and evaluates three established OCR approaches, Transkribus, Tesseract and TrOCR, for transcribing S\'ami texts from NLN's collection. Our results show that Transkribus and TrOCR outperform Tesseract on this task, while Tesseract achieves superior performance on an out-of-domain dataset. Furthermore, we show that fine-tuning pre-trained models and supplementing manual annotations with machine annotations and synthetic text images can yield accurate OCR for S\'ami languages, even with a moderate amount of manually annotated data.