 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling State-Space Models from Lines to Paragraphs: An Ablation of Mamba-based OCR
Jun 22, 2026End-to-end OCR increasingly relies on autoregressive sequence models, where the quadratic cost of Transformer attention limits efficient transcription of long, paragraph-level text. State-Space Models (SSMs) such as Mamba offer linear-time decoding and have recently been shown to match Transformer accuracy on printed historical lines, but their behavior as sequences grow from short lines to full paragraphs, and their generalization to handwriting, remain poorly understood. We study how a Mamba-based OCR recognizer scales from lines to paragraphs. We first conduct a systematic exploration of its four core hyperparameters (decoder depth, state dimension, expansion factor, and connector depth) on synthetic paragraphs from 100 to 1,000 characters, identifying the recurrent state dimension and the expansion factor as the dominant levers for long-sequence accuracy. We then compare the recognizer against a Transformer baseline trained under an identical protocol. On clean synthetic paragraphs, both models stay below 1% CER at every length while the SSM runs 1.4 to 4.5 times faster, the speedup growing with sequence length. On real handwriting, however, the SSM lags clearly behind: it reaches 8.2% CER on IAM lines and 10.0% on IAM paragraphs, against 4.2% and 3.5% for the Transformer baseline. Through controlled experiments we show that a substantial part of this gap stems from data scarcity rather than from an intrinsic architectural limit: the autoregressive SSM decoder is markedly data-hungry on long sequences. Our study clarifies when SSMs are a practical choice for large-scale document transcription and when they are not.
A Benchmark of State-Space Models vs. Transformers and BiLSTM-based Models for Historical Newspaper OCR
Apr 01, 2026End-to-end OCR for historical newspapers remains challenging, as models must handle long text sequences, degraded print quality, and complex layouts. While Transformer-based recognizers dominate current research, their quadratic complexity limits efficient paragraph-level transcription and large-scale deployment. We investigate linear-time State-Space Models (SSMs), specifically Mamba, as a scalable alternative to Transformer-based sequence modeling for OCR. We present to our knowledge, the first OCR architecture based on SSMs, combining a CNN visual encoder with bi-directional and autoregressive Mamba sequence modeling, and conduct a large-scale benchmark comparing SSMs with Transformer- and BiLSTM-based recognizers. Multiple decoding strategies (CTC, autoregressive, and non-autoregressive) are evaluated under identical training conditions alongside strong neural baselines (VAN, DAN, DANIEL) and widely used off-the-shelf OCR engines (PERO-OCR, Tesseract OCR, TrOCR, Gemini). Experiments on historical newspapers from the Bibliothèque nationale du Luxembourg, with newly released >99% verified gold-standard annotations, and cross-dataset tests on Fraktur and Antiqua lines, show that all neural models achieve low error rates (~2% CER), making computational efficiency the main differentiator. Mamba-based models maintain competitive accuracy while halving inference time and exhibiting superior memory scaling (1.26x vs 2.30x growth at 1000 chars), reaching 6.07% CER at the severely degraded paragraph level compared to 5.24% for DAN, while remaining 2.05x faster. We release code, trained models, and standardized evaluation protocols to enable reproducible research and guide practitioners in large-scale cultural heritage OCR.
Pattern Spotting in Historical Documents Using Convolutional Models
Jun 20, 2019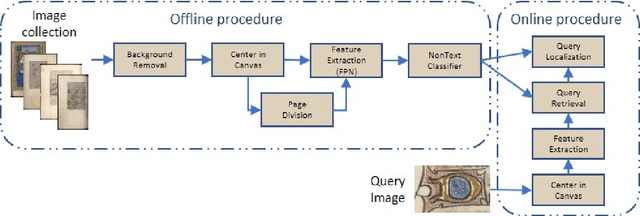
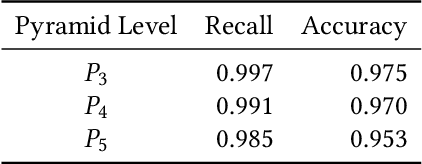


Pattern spotting consists of searching in a collection of historical document images for occurrences of a graphical object using an image query. Contrary to object detection, no prior information nor predefined class is given about the query so training a model of the object is not feasible. In this paper, a convolutional neural network approach is proposed to tackle this problem. We use RetinaNet as a feature extractor to obtain multiscale embeddings of the regions of the documents and also for the queries. Experiments conducted on the DocExplore dataset show that our proposal is better at locating patterns and requires less storage for indexing images than the state-of-the-art system, but fails at retrieving some pages containing multiple instances of the query.
Logical segmentation for article extraction in digitized old newspapers
Oct 03, 2012
Newspapers are documents made of news item and informative articles. They are not meant to be red iteratively: the reader can pick his items in any order he fancies. Ignoring this structural property, most digitized newspaper archives only offer access by issue or at best by page to their content. We have built a digitization workflow that automatically extracts newspaper articles from images, which allows indexing and retrieval of information at the article level. Our back-end system extracts the logical structure of the page to produce the informative units: the articles. Each image is labelled at the pixel level, through a machine learning based method, then the page logical structure is constructed up from there by the detection of structuring entities such as horizontal and vertical separators, titles and text lines. This logical structure is stored in a METS wrapper associated to the ALTO file produced by the system including the OCRed text. Our front-end system provides a web high definition visualisation of images, textual indexing and retrieval facilities, searching and reading at the article level. Articles transcriptions can be collaboratively corrected, which as a consequence allows for better indexing. We are currently testing our system on the archives of the Journal de Rouen, one of France eldest local newspaper. These 250 years of publication amount to 300 000 pages of very variable image quality and layout complexity. Test year 1808 can be consulted at plair.univ-rouen.fr.