 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrademark Retrieval
Papers and Code
Segment Augmentation and Differentiable Ranking for Logo Retrieval
Sep 13, 2022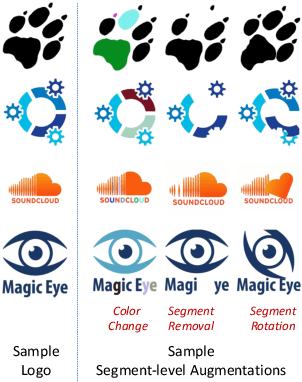
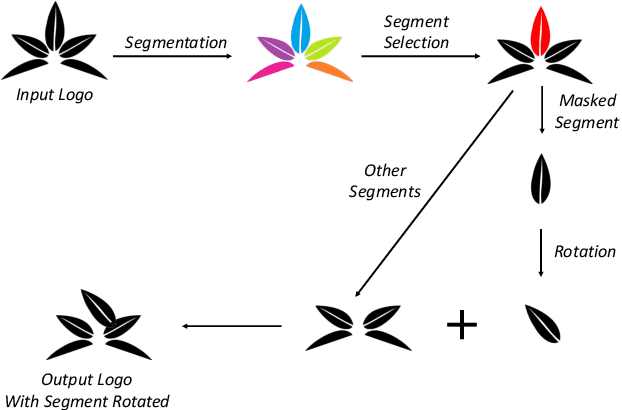
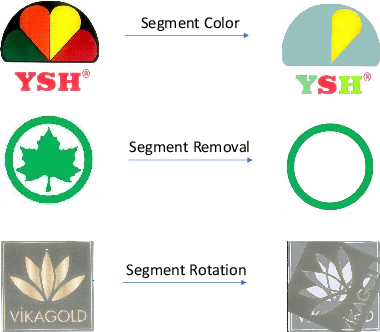
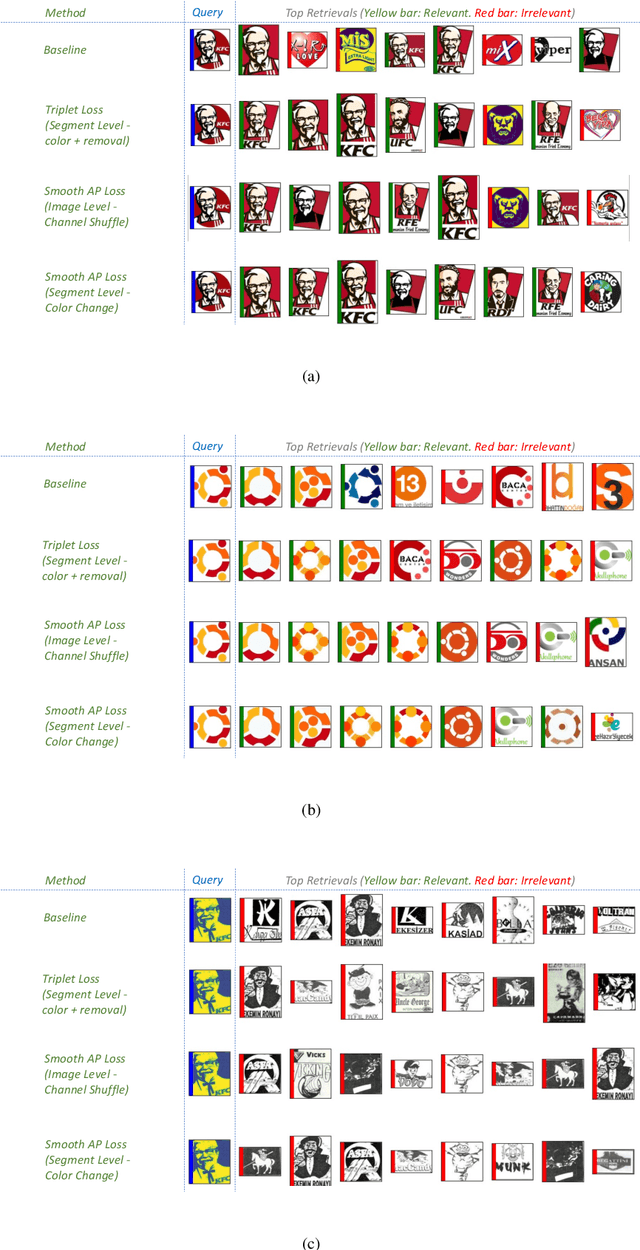
Logo retrieval is a challenging problem since the definition of similarity is more subjective compared to image retrieval tasks and the set of known similarities is very scarce. To tackle this challenge, in this paper, we propose a simple but effective segment-based augmentation strategy to introduce artificially similar logos for training deep networks for logo retrieval. In this novel augmentation strategy, we first find segments in a logo and apply transformations such as rotation, scaling, and color change, on the segments, unlike the conventional image-level augmentation strategies. Moreover, we evaluate whether the recently introduced ranking-based loss function, Smooth-AP, is a better approach for learning similarity for logo retrieval. On the large scale METU Trademark Dataset, we show that (i) our segment-based augmentation strategy improves retrieval performance compared to the baseline model or image-level augmentation strategies, and (ii) Smooth-AP indeed performs better than conventional losses for logo retrieval.
Learning Regional Attention over Multi-resolution Deep Convolutional Features for Trademark Retrieval
Apr 15, 2021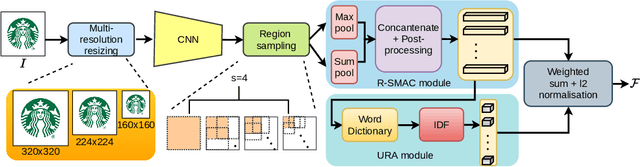
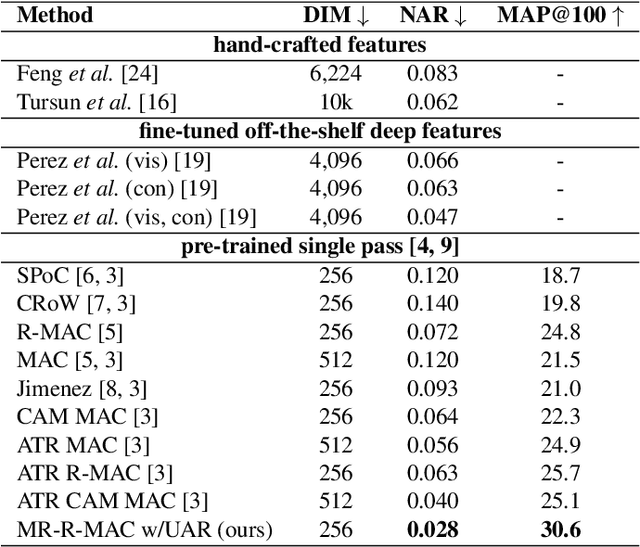

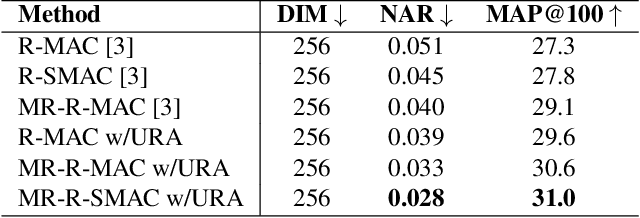
Large-scale trademark retrieval is an important content-based image retrieval task. A recent study shows that off-the-shelf deep features aggregated with Regional-Maximum Activation of Convolutions (R-MAC) achieve state-of-the-art results. However, R-MAC suffers in the presence of background clutter/trivial regions and scale variance, and discards important spatial information. We introduce three simple but effective modifications to R-MAC to overcome these drawbacks. First, we propose the use of both sum and max pooling to minimise the loss of spatial information. We also employ domain-specific unsupervised soft-attention to eliminate background clutter and unimportant regions. Finally, we add multi-resolution inputs to enhance the scale-invariance of R-MAC. We evaluate these three modifications on the million-scale METU dataset. Our results show that all modifications bring non-trivial improvements, and surpass previous state-of-the-art results.
Multi-Label Logo Recognition and Retrieval based on Weighted Fusion of Neural Features
May 11, 2022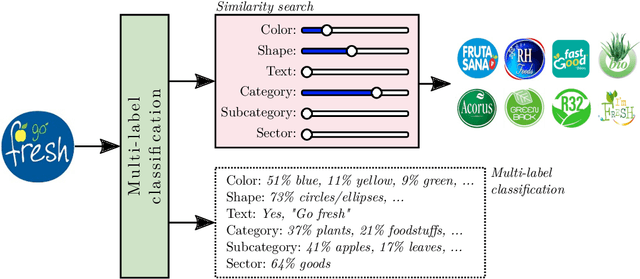

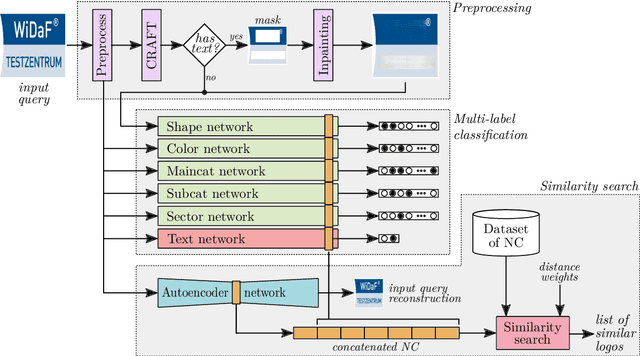
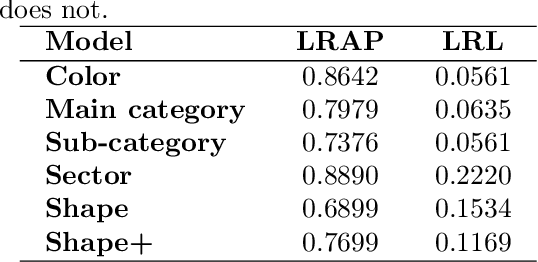
Logo classification is a particular case of image classification, since these may contain only text, images, or a combination of both. In this work, we propose a system for the multi-label classification and similarity search of logo images. The method allows obtaining the most similar logos on the basis of their shape, color, business sector, semantics, general characteristics, or a combination of such features established by the user. This is done by employing a set of multi-label networks specialized in certain characteristics of logos. The features extracted from these networks are combined to perform the similarity search according to the search criteria established. Since the text of logos is sometimes irrelevant for the classification, a preprocessing stage is carried out to remove it, thus improving the overall performance. The proposed approach is evaluated using the European Union Trademark (EUTM) dataset, structured with the hierarchical Vienna classification system, which includes a series of metadata with which to index trademarks. We also make a comparison between well known logo topologies and Vienna in order to help designers understand their correspondences. The experimentation carried out attained reliable performance results, both quantitatively and qualitatively, which outperformed the state-of-the-art results. In addition, since the semantics and classification of brands can often be subjective, we also surveyed graphic design students and professionals in order to assess the reliability of the proposed method.
Hierarchy-of-Visual-Words: a Learning-based Approach for Trademark Image Retrieval
Aug 07, 2019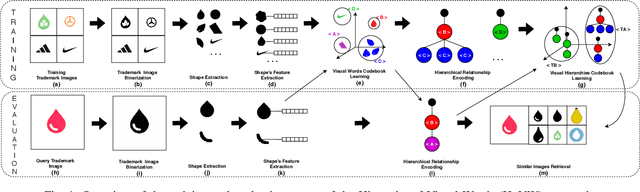
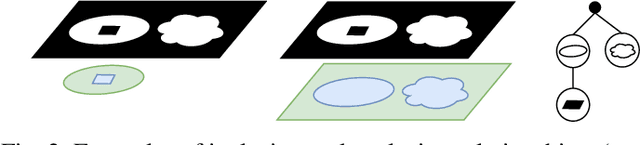

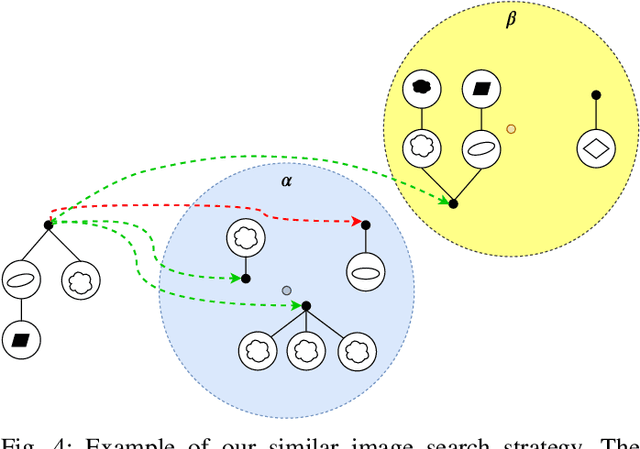
In this paper, we present the Hierarchy-of-Visual-Words (HoVW), a novel trademark image retrieval (TIR) method that decomposes images into simpler geometric shapes and defines a descriptor for binary trademark image representation by encoding the hierarchical arrangement of component shapes. The proposed hierarchical organization of visual data stores each component shape as a visual word. It is capable of representing the geometry of individual elements and the topology of the trademark image, making the descriptor robust against linear as well as to some level of nonlinear transformation. Experiments show that HoVW outperforms previous TIR methods on the MPEG-7 CE-1 and MPEG-7 CE-2 image databases.
Component-based Attention for Large-scale Trademark Retrieval
Nov 07, 2018


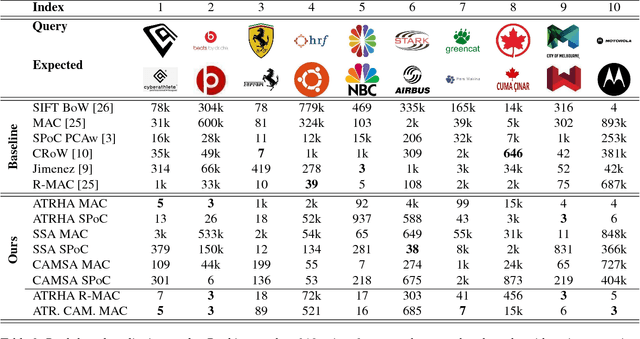
The demand for large-scale trademark retrieval (TR) systems has significantly increased to combat the rise in international trademark infringement. Unfortunately, the ranking accuracy of current approaches using either hand-crafted or pre-trained deep convolution neural network (DCNN) features is inadequate for large-scale deployments. We show in this paper that the ranking accuracy of TR systems can be significantly improved by incorporating hard and soft attention mechanisms, which direct attention to critical information such as figurative elements and reduce attention given to distracting and uninformative elements such as text and background. Our proposed approach achieves state-of-the-art results on a challenging large-scale trademark dataset.
A Large-scale Dataset and Benchmark for Similar Trademark Retrieval
Oct 14, 2017
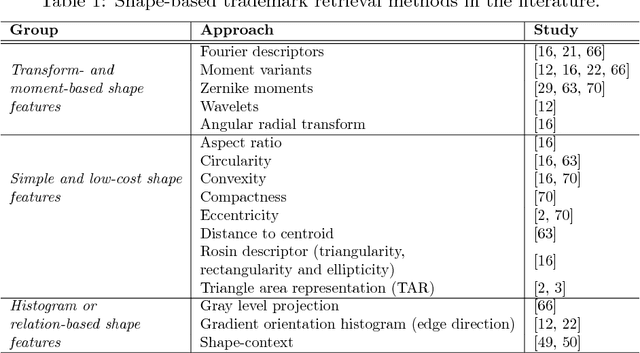
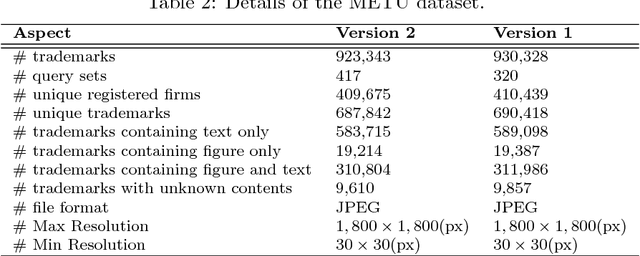
Trademark retrieval (TR) has become an important yet challenging problem due to an ever increasing trend in trademark applications and infringement incidents. There have been many promising attempts for the TR problem, which, however, fell impracticable since they were evaluated with limited and mostly trivial datasets. In this paper, we provide a large-scale dataset with benchmark queries with which different TR approaches can be evaluated systematically. Moreover, we provide a baseline on this benchmark using the widely-used methods applied to TR in the literature. Furthermore, we identify and correct two important issues in TR approaches that were not addressed before: reversal of contrast, and presence of irrelevant text in trademarks severely affect the TR methods. Lastly, we applied deep learning, namely, several popular Convolutional Neural Network models, to the TR problem. To the best of the authors, this is the first attempt to do so.
Efficient Retrieval of Logos Using Rough Set Reducts
Apr 10, 2019

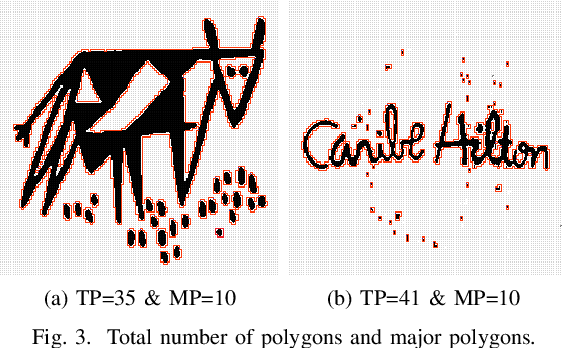

Searching for similar logos in the registered logo database is a very important and tedious task at the trademark office. Speed and accuracy are two aspects that one must attend to while developing a system for retrieval of logos. In this paper, we propose a rough-set based method to quantify the structural information in a logo image that can be used to efficiently index an image. A logo is split into a number of polygons, and for each polygon, we compute the tight upper and lower approximations based on the principles of a rough set. This representation is used for forming feature vectors for retrieval of logos. Experimentation on a standard data set shows the usefulness of the proposed technique. It is computationally efficient and also provides retrieval results at high accuracy.
A Novel Approach to Develop a New Hybrid Technique for Trademark Image Retrieval
Nov 08, 2014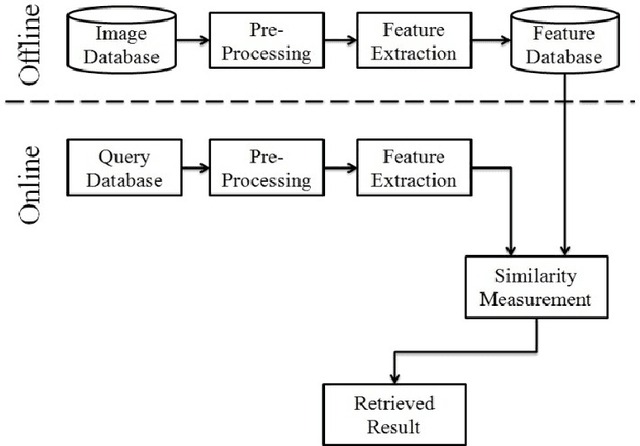
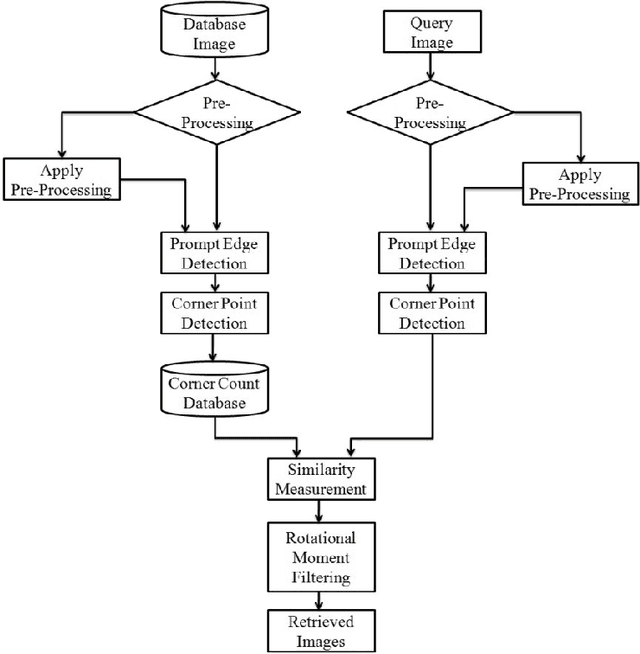
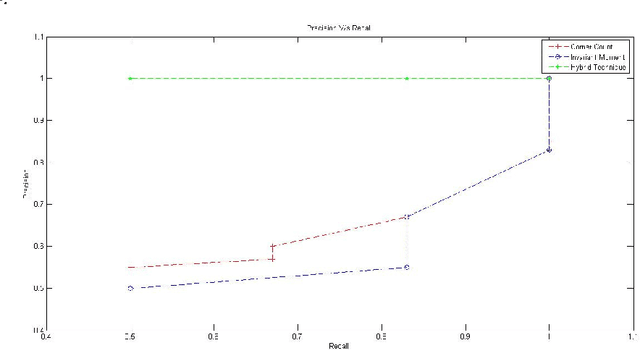
Trademark Image Retrieval is playing a vital role as a part of CBIR System. Trademark is of great significance because it carries the status value of any company. To retrieve such a fake or copied trademark we design a retrieval system which is based on hybrid techniques. It contains a mixture of two different feature vector which combined together to give a suitable retrieval system. In the proposed system we extract the corner feature which is applied on an edge pixel image. This feature is used to extract the relevant image and to more purify the result we apply other feature which is the invariant moment feature. From the experimental result we conclude that the system is 85 percent efficient.