 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformalLayers: A non-linear sequential neural network with associative layers
Nov 09, 2021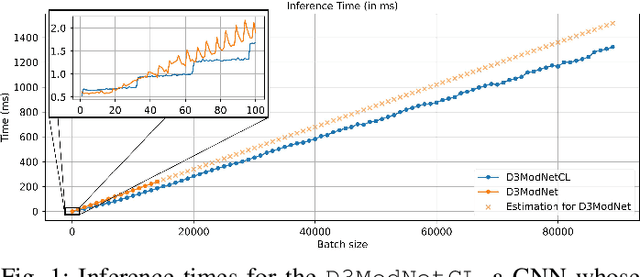
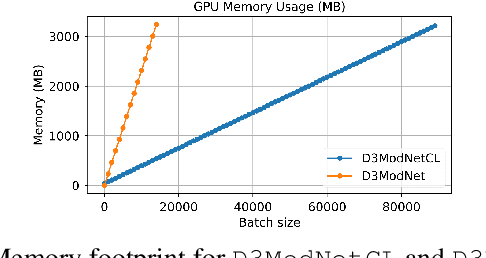
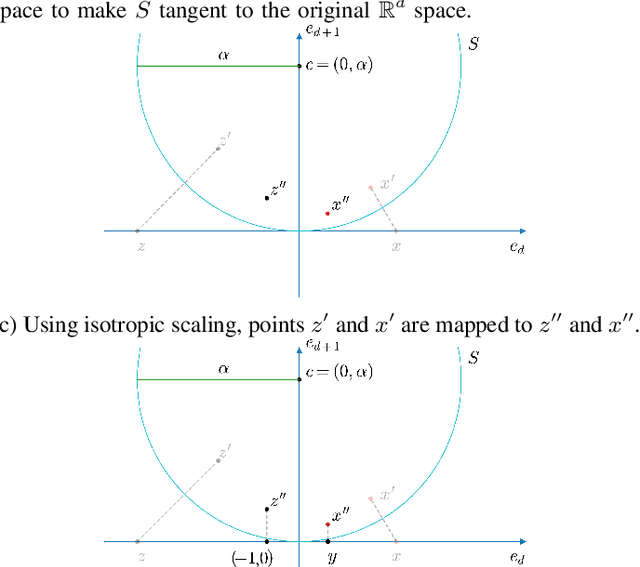
Convolutional Neural Networks (CNNs) have been widely applied. But as the CNNs grow, the number of arithmetic operations and memory footprint also increase. Furthermore, typical non-linear activation functions do not allow associativity of the operations encoded by consecutive layers, preventing the simplification of intermediate steps by combining them. We present a new activation function that allows associativity between sequential layers of CNNs. Even though our activation function is non-linear, it can be represented by a sequence of linear operations in the conformal model for Euclidean geometry. In this domain, operations like, but not limited to, convolution, average pooling, and dropout remain linear. We take advantage of associativity to combine all the "conformal layers" and make the cost of inference constant regardless of the depth of the network.
Hierarchy-of-Visual-Words: a Learning-based Approach for Trademark Image Retrieval
Aug 07, 2019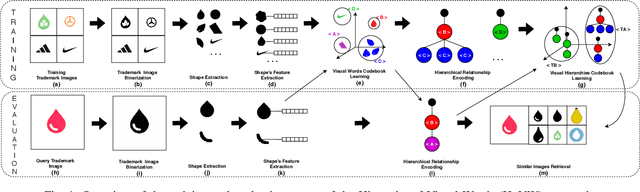
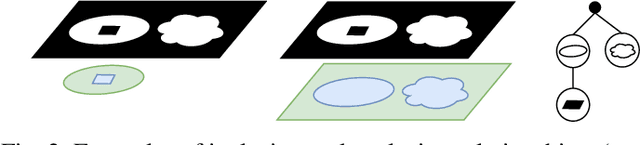

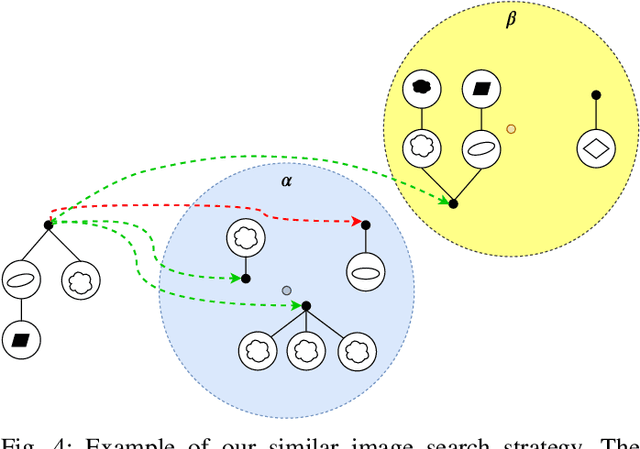
In this paper, we present the Hierarchy-of-Visual-Words (HoVW), a novel trademark image retrieval (TIR) method that decomposes images into simpler geometric shapes and defines a descriptor for binary trademark image representation by encoding the hierarchical arrangement of component shapes. The proposed hierarchical organization of visual data stores each component shape as a visual word. It is capable of representing the geometry of individual elements and the topology of the trademark image, making the descriptor robust against linear as well as to some level of nonlinear transformation. Experiments show that HoVW outperforms previous TIR methods on the MPEG-7 CE-1 and MPEG-7 CE-2 image databases.