 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToronto Neuroface Dataset
Papers and Code
DIVINE: Coordinating Multimodal Disentangled Representations for Oro-Facial Neurological Disorder Assessment
Jan 11, 2026In this study, we present a multimodal framework for predicting neuro-facial disorders by capturing both vocal and facial cues. We hypothesize that explicitly disentangling shared and modality-specific representations within multimodal foundation model embeddings can enhance clinical interpretability and generalization. To validate this hypothesis, we propose DIVINE a fully disentangled multimodal framework that operates on representations extracted from state-of-the-art (SOTA) audio and video foundation models, incorporating hierarchical variational bottlenecks, sparse gated fusion, and learnable symptom tokens. DIVINE operates in a multitask learning setup to jointly predict diagnostic categories (Healthy Control,ALS, Stroke) and severity levels (Mild, Moderate, Severe). The model is trained using synchronized audio and video inputs and evaluated on the Toronto NeuroFace dataset under full (audio-video) as well as single-modality (audio-only and video-only) test conditions. Our proposed approach, DIVINE achieves SOTA result, with the DeepSeek-VL2 and TRILLsson combination reaching 98.26% accuracy and 97.51% F1-score. Under modality-constrained scenarios, the framework performs well, showing strong generalization when tested with video-only or audio-only inputs. It consistently yields superior performance compared to unimodal models and baseline fusion techniques. To the best of our knowledge, DIVINE is the first framework that combines cross-modal disentanglement, adaptive fusion, and multitask learning to comprehensively assess neurological disorders using synchronized speech and facial video.
Trajectory-guided Motion Perception for Facial Expression Quality Assessment in Neurological Disorders
Apr 16, 2025Automated facial expression quality assessment (FEQA) in neurological disorders is critical for enhancing diagnostic accuracy and improving patient care, yet effectively capturing the subtle motions and nuances of facial muscle movements remains a challenge. We propose to analyse facial landmark trajectories, a compact yet informative representation, that encodes these subtle motions from a high-level structural perspective. Hence, we introduce Trajectory-guided Motion Perception Transformer (TraMP-Former), a novel FEQA framework that fuses landmark trajectory features for fine-grained motion capture with visual semantic cues from RGB frames, ultimately regressing the combined features into a quality score. Extensive experiments demonstrate that TraMP-Former achieves new state-of-the-art performance on benchmark datasets with neurological disorders, including PFED5 (up by 6.51%) and an augmented Toronto NeuroFace (up by 7.62%). Our ablation studies further validate the efficiency and effectiveness of landmark trajectories in FEQA. Our code is available at https://github.com/shuchaoduan/TraMP-Former.
A store-and-forward cloud-based telemonitoring system for automatic assessing dysarthria evolution in neurological diseases from video-recording analysis
Sep 16, 2023Background and objectives: Patients suffering from neurological diseases may develop dysarthria, a motor speech disorder affecting the execution of speech. Close and quantitative monitoring of dysarthria evolution is crucial for enabling clinicians to promptly implement patient management strategies and maximizing effectiveness and efficiency of communication functions in term of restoring, compensating or adjusting. In the clinical assessment of orofacial structures and functions, at rest condition or during speech and non-speech movements, a qualitative evaluation is usually performed, throughout visual observation. Methods: To overcome limitations posed by qualitative assessments, this work presents a store-and-forward self-service telemonitoring system that integrates, within its cloud architecture, a convolutional neural network (CNN) for analyzing video recordings acquired by individuals with dysarthria. This architecture, called facial landmark Mask RCNN, aims at locating facial landmarks as a prior for assessing the orofacial functions related to speech and examining dysarthria evolution in neurological diseases. Results: When tested on the Toronto NeuroFace dataset, a publicly available annotated dataset of video recordings from patients with amyotrophic lateral sclerosis (ALS) and stroke, the proposed CNN achieved a normalized mean error equal to 1.79 on localizing the facial landmarks. We also tested our system in a real-life scenario on 11 bulbar-onset ALS subjects, obtaining promising outcomes in terms of facial landmark position estimation. Discussion and conclusions: This preliminary study represents a relevant step towards the use of remote tools to support clinicians in monitoring the evolution of dysarthria.
Facial Point Graphs for Amyotrophic Lateral Sclerosis Identification
Jul 22, 2023Identifying Amyotrophic Lateral Sclerosis (ALS) in its early stages is essential for establishing the beginning of treatment, enriching the outlook, and enhancing the overall well-being of those affected individuals. However, early diagnosis and detecting the disease's signs is not straightforward. A simpler and cheaper way arises by analyzing the patient's facial expressions through computational methods. When a patient with ALS engages in specific actions, e.g., opening their mouth, the movement of specific facial muscles differs from that observed in a healthy individual. This paper proposes Facial Point Graphs to learn information from the geometry of facial images to identify ALS automatically. The experimental outcomes in the Toronto Neuroface dataset show the proposed approach outperformed state-of-the-art results, fostering promising developments in the area.
Automated Temporal Segmentation of Orofacial Assessment Videos
Aug 22, 2022
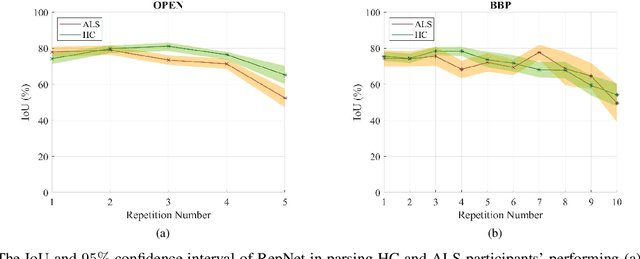
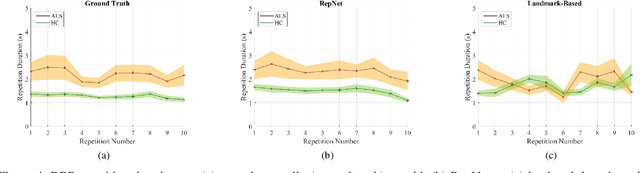
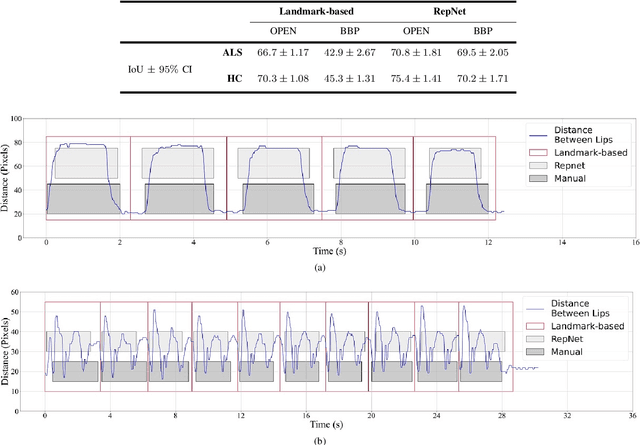
Computer vision techniques can help automate or partially automate clinical examination of orofacial impairments to provide accurate and objective assessments. Towards the development of such automated systems, we evaluated two approaches to detect and temporally segment (parse) repetitions in orofacial assessment videos. Recorded videos of participants with amyotrophic lateral sclerosis (ALS) and healthy control (HC) individuals were obtained from the Toronto NeuroFace Dataset. Two approaches for repetition detection and parsing were examined: one based on engineered features from tracked facial landmarks and peak detection in the distance between the vermilion-cutaneous junction of the upper and lower lips (baseline analysis), and another using a pre-trained transformer-based deep learning model called RepNet (Dwibedi et al, 2020), which automatically detects periodicity, and parses periodic and semi-periodic repetitions in video data. In experimental evaluation of two orofacial assessments tasks, - repeating maximum mouth opening (OPEN) and repeating the sentence "Buy Bobby a Puppy" (BBP) - RepNet provided better parsing than the landmark-based approach, quantified by higher mean intersection-over-union (IoU) with respect to ground truth manual parsing. Automated parsing using RepNet also clearly separated HC and ALS participants based on the duration of BBP repetitions, whereas the landmark-based method could not.