 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNinapro Db2
Papers and Code
SASG-DA: Sparse-Aware Semantic-Guided Diffusion Augmentation For Myoelectric Gesture Recognition
Nov 12, 2025Surface electromyography (sEMG)-based gesture recognition plays a critical role in human-machine interaction (HMI), particularly for rehabilitation and prosthetic control. However, sEMG-based systems often suffer from the scarcity of informative training data, leading to overfitting and poor generalization in deep learning models. Data augmentation offers a promising approach to increasing the size and diversity of training data, where faithfulness and diversity are two critical factors to effectiveness. However, promoting untargeted diversity can result in redundant samples with limited utility. To address these challenges, we propose a novel diffusion-based data augmentation approach, Sparse-Aware Semantic-Guided Diffusion Augmentation (SASG-DA). To enhance generation faithfulness, we introduce the Semantic Representation Guidance (SRG) mechanism by leveraging fine-grained, task-aware semantic representations as generation conditions. To enable flexible and diverse sample generation, we propose a Gaussian Modeling Semantic Sampling (GMSS) strategy, which models the semantic representation distribution and allows stochastic sampling to produce both faithful and diverse samples. To enhance targeted diversity, we further introduce a Sparse-Aware Semantic Sampling (SASS) strategy to explicitly explore underrepresented regions, improving distribution coverage and sample utility. Extensive experiments on benchmark sEMG datasets, Ninapro DB2, DB4, and DB7, demonstrate that SASG-DA significantly outperforms existing augmentation methods. Overall, our proposed data augmentation approach effectively mitigates overfitting and improves recognition performance and generalization by offering both faithful and diverse samples.
Electromyography-Based Gesture Recognition: Hierarchical Feature Extraction for Enhanced Spatial-Temporal Dynamics
Apr 04, 2025Hand gesture recognition using multichannel surface electromyography (sEMG) is challenging due to unstable predictions and inefficient time-varying feature enhancement. To overcome the lack of signal based time-varying feature problems, we propose a lightweight squeeze-excitation deep learning-based multi stream spatial temporal dynamics time-varying feature extraction approach to build an effective sEMG-based hand gesture recognition system. Each branch of the proposed model was designed to extract hierarchical features, capturing both global and detailed spatial-temporal relationships to ensure feature effectiveness. The first branch, utilizing a Bidirectional-TCN (Bi-TCN), focuses on capturing long-term temporal dependencies by modelling past and future temporal contexts, providing a holistic view of gesture dynamics. The second branch, incorporating a 1D Convolutional layer, separable CNN, and Squeeze-and-Excitation (SE) block, efficiently extracts spatial-temporal features while emphasizing critical feature channels, enhancing feature relevance. The third branch, combining a Temporal Convolutional Network (TCN) and Bidirectional LSTM (BiLSTM), captures bidirectional temporal relationships and time-varying patterns. Outputs from all branches are fused using concatenation to capture subtle variations in the data and then refined with a channel attention module, selectively focusing on the most informative features while improving computational efficiency. The proposed model was tested on the Ninapro DB2, DB4, and DB5 datasets, achieving accuracy rates of 96.41%, 92.40%, and 93.34%, respectively. These results demonstrate the capability of the system to handle complex sEMG dynamics, offering advancements in prosthetic limb control and human-machine interface technologies with significant implications for assistive technologies.
An LSTM Feature Imitation Network for Hand Movement Recognition from sEMG Signals
May 23, 2024



Surface Electromyography (sEMG) is a non-invasive signal that is used in the recognition of hand movement patterns, the diagnosis of diseases, and the robust control of prostheses. Despite the remarkable success of recent end-to-end Deep Learning approaches, they are still limited by the need for large amounts of labeled data. To alleviate the requirement for big data, researchers utilize Feature Engineering, which involves decomposing the sEMG signal into several spatial, temporal, and frequency features. In this paper, we propose utilizing a feature-imitating network (FIN) for closed-form temporal feature learning over a 300ms signal window on Ninapro DB2, and applying it to the task of 17 hand movement recognition. We implement a lightweight LSTM-FIN network to imitate four standard temporal features (entropy, root mean square, variance, simple square integral). We then explore transfer learning capabilities by applying the pre-trained LSTM-FIN for tuning to a downstream hand movement recognition task. We observed that the LSTM network can achieve up to 99\% R2 accuracy in feature reconstruction and 80\% accuracy in hand movement recognition. Our results also showed that the model can be robustly applied for both within- and cross-subject movement recognition, as well as simulated low-latency environments. Overall, our work demonstrates the potential of the FIN modeling paradigm in data-scarce scenarios for sEMG signal processing.
An Evolutionary Network Architecture Search Framework with Adaptive Multimodal Fusion for Hand Gesture Recognition
Mar 27, 2024



Hand gesture recognition (HGR) based on multimodal data has attracted considerable attention owing to its great potential in applications. Various manually designed multimodal deep networks have performed well in multimodal HGR (MHGR), but most of existing algorithms require a lot of expert experience and time-consuming manual trials. To address these issues, we propose an evolutionary network architecture search framework with the adaptive multimodel fusion (AMF-ENAS). Specifically, we design an encoding space that simultaneously considers fusion positions and ratios of the multimodal data, allowing for the automatic construction of multimodal networks with different architectures through decoding. Additionally, we consider three input streams corresponding to intra-modal surface electromyography (sEMG), intra-modal accelerometer (ACC), and inter-modal sEMG-ACC. To automatically adapt to various datasets, the ENAS framework is designed to automatically search a MHGR network with appropriate fusion positions and ratios. To the best of our knowledge, this is the first time that ENAS has been utilized in MHGR to tackle issues related to the fusion position and ratio of multimodal data. Experimental results demonstrate that AMF-ENAS achieves state-of-the-art performance on the Ninapro DB2, DB3, and DB7 datasets.
TEMGNet: Deep Transformer-based Decoding of Upperlimb sEMG for Hand Gestures Recognition
Sep 25, 2021
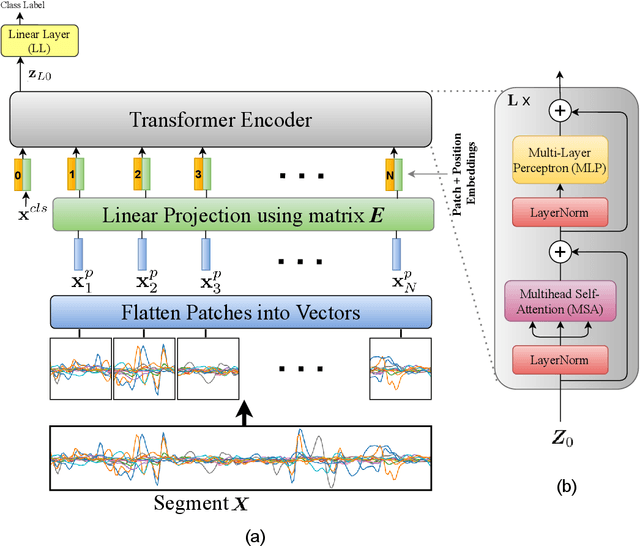
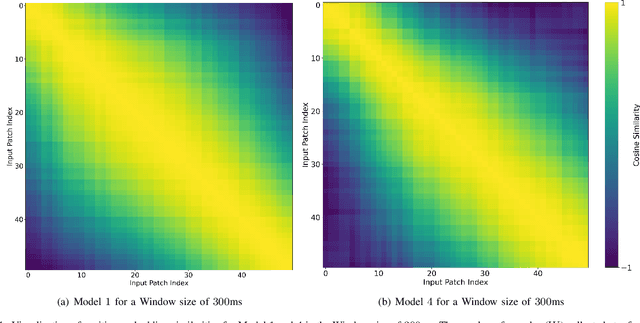
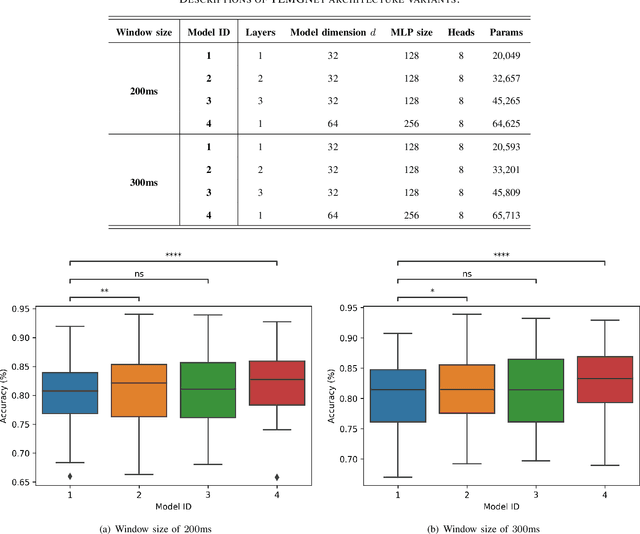
There has been a surge of recent interest in Machine Learning (ML), particularly Deep Neural Network (DNN)-based models, to decode muscle activities from surface Electromyography (sEMG) signals for myoelectric control of neurorobotic systems. DNN-based models, however, require large training sets and, typically, have high structural complexity, i.e., they depend on a large number of trainable parameters. To address these issues, we developed a framework based on the Transformer architecture for processing sEMG signals. We propose a novel Vision Transformer (ViT)-based neural network architecture (referred to as the TEMGNet) to classify and recognize upperlimb hand gestures from sEMG to be used for myocontrol of prostheses. The proposed TEMGNet architecture is trained with a small dataset without the need for pre-training or fine-tuning. To evaluate the efficacy, following the-recent literature, the second subset (exercise B) of the NinaPro DB2 dataset was utilized, where the proposed TEMGNet framework achieved a recognition accuracy of 82.93% and 82.05% for window sizes of 300ms and 200ms, respectively, outperforming its state-of-the-art counterparts. Moreover, the proposed TEMGNet framework is superior in terms of structural capacity while having seven times fewer trainable parameters. These characteristics and the high performance make DNN-based models promising approaches for myoelectric control of neurorobots.
TraHGR: Transformer for Hand Gesture Recognition via ElectroMyography
Mar 31, 2022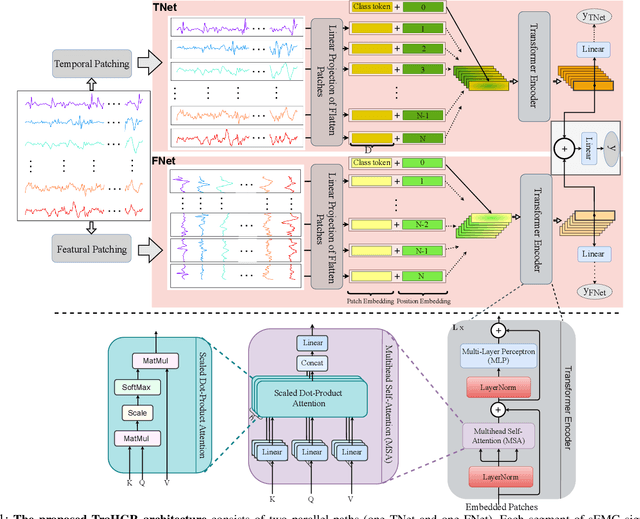
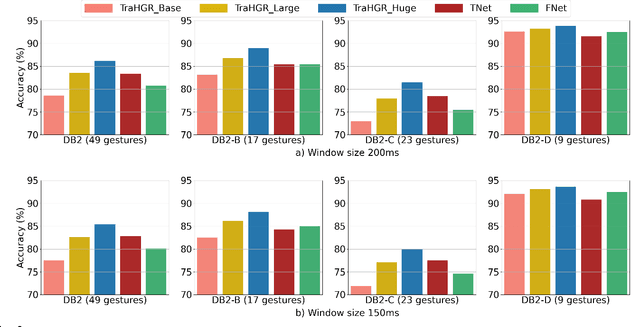
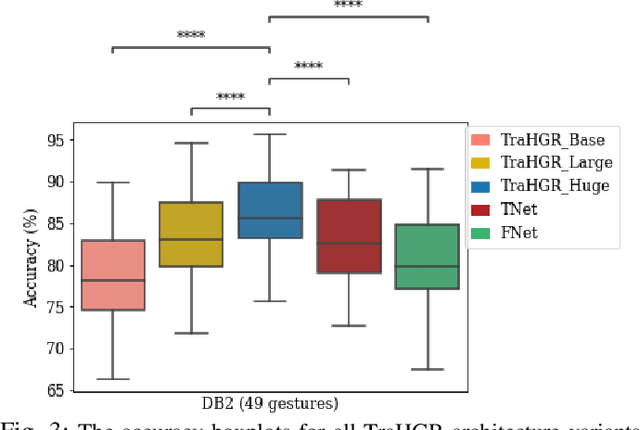
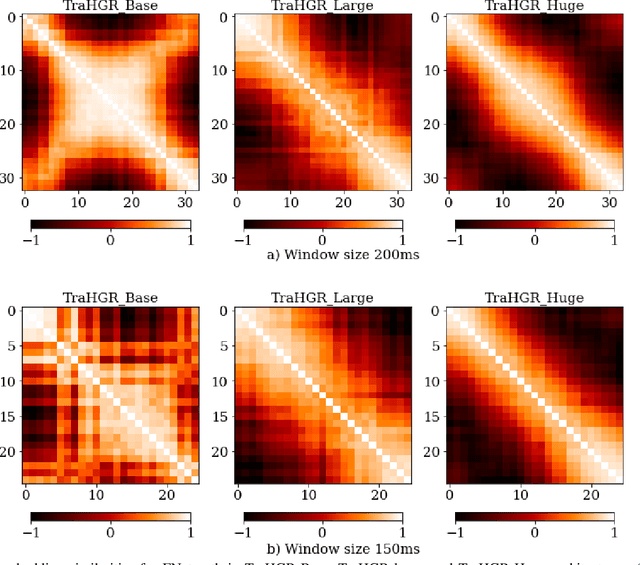
Deep learning-based Hand Gesture Recognition (HGR) via surface Electromyogram (sEMG) signals has recently shown significant potential for development of advanced myoelectric-controlled prosthesis. Existing deep learning approaches, typically, include only one model as such can hardly maintain acceptable generalization performance in changing scenarios. In this paper, we aim to address this challenge by capitalizing on the recent advances of hybrid models and transformers. In other words, we propose a hybrid framework based on the transformer architecture, which is a relatively new and revolutionizing deep learning model. The proposed hybrid architecture, referred to as the Transformer for Hand Gesture Recognition (TraHGR), consists of two parallel paths followed by a linear layer that acts as a fusion center to integrate the advantage of each module and provide robustness over different scenarios. We evaluated the proposed architecture TraHGR based on the commonly used second Ninapro dataset, referred to as the DB2. The sEMG signals in the DB2 dataset are measured in the real-life conditions from 40 healthy users, each performing 49 gestures. We have conducted extensive set of experiments to test and validate the proposed TraHGR architecture, and have compared its achievable accuracy with more than five recently proposed HGR classification algorithms over the same dataset. We have also compared the results of the proposed TraHGR architecture with each individual path and demonstrated the distinguishing power of the proposed hybrid architecture. The recognition accuracies of the proposed TraHGR architecture are 86.18%, 88.91%, 81.44%, and 93.84%, which are 2.48%, 5.12%, 8.82%, and 4.30% higher than the state-ofthe-art performance for DB2 (49 gestures), DB2-B (17 gestures), DB2-C (23 gestures), and DB2-D (9 gestures), respectively.
A Robust and Accurate Deep Learning based Pattern Recognition Framework for Upper Limb Prosthesis using sEMG
Jun 11, 2021
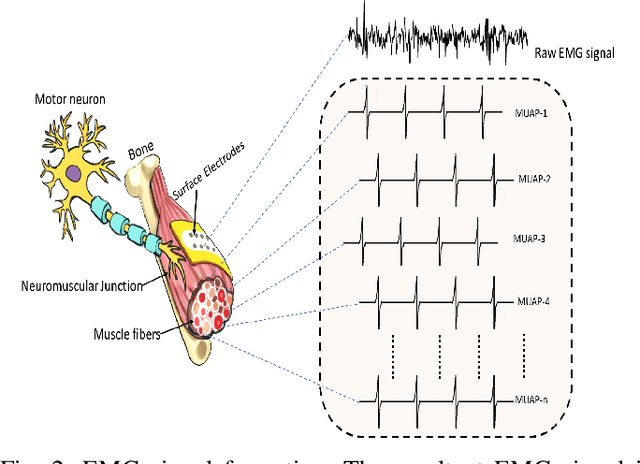
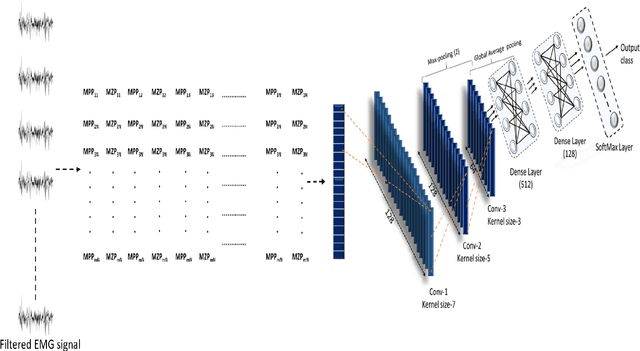
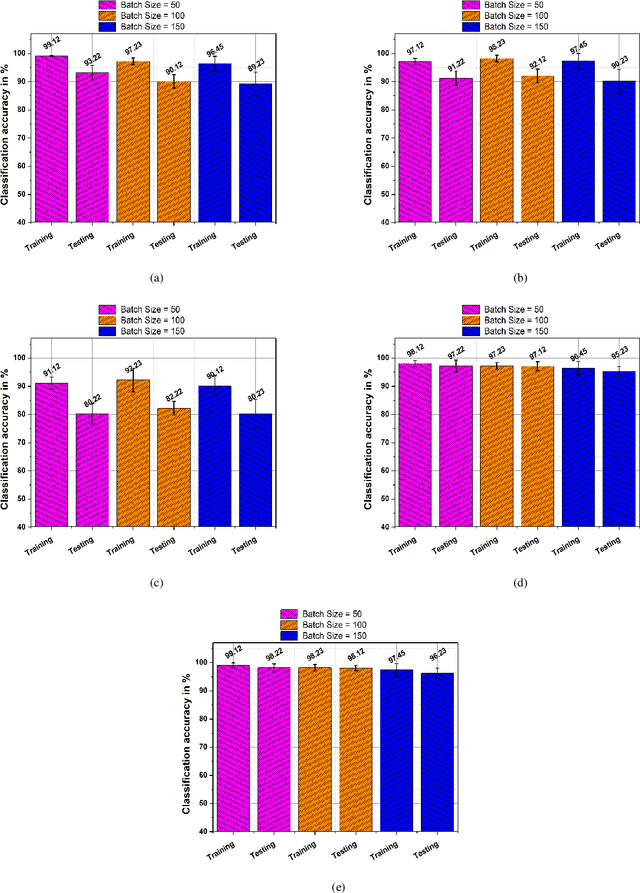
In EMG based pattern recognition (EMG-PR), deep learning-based techniques have become more prominent for their self-regulating capability to extract discriminant features from large data-sets. Moreover, the performance of traditional machine learning-based methods show limitation to categorize over a certain number of classes and degrades over a period of time. In this paper, an accurate, robust, and fast convolutional neural network-based framework for EMG pattern identification is presented. To assess the performance of the proposed system, five publicly available and benchmark data-sets of upper limb activities were used. This data-set contains 49 to 52 upper limb motions (NinaPro DB1, NinaPro DB2, and NinaPro DB3), Data with force variation, and data with arm position variation for intact and amputated subjects. The classification accuracies of 91.11% (53 classes), 89.45% (49 classes), 81.67% (49 classes of amputees), 95.67% (6 classes with force variation), and 99.11% (8 classes with arm position variation) have been observed during the testing and validation. The performance of the proposed system is compared with the state of art techniques in the literature. The findings demonstrate that classification accuracy and time complexity have improved significantly. Keras, TensorFlow's high-level API for constructing deep learning models, was used for signal pre-processing and deep-learning-based algorithms. The suggested method was run on an Intel 3.5GHz Core i7, 7th Gen CPU with 8GB DDR4 RAM.