 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Phone Dataset Smartphone Feature Phone
Papers and Code
A Comparative Study of Traditional Machine Learning, Deep Learning, and Large Language Models for Mental Health Forecasting using Smartphone Sensing Data
Jan 07, 2026Smartphone sensing offers an unobtrusive and scalable way to track daily behaviors linked to mental health, capturing changes in sleep, mobility, and phone use that often precede symptoms of stress, anxiety, or depression. While most prior studies focus on detection that responds to existing conditions, forecasting mental health enables proactive support through Just-in-Time Adaptive Interventions. In this paper, we present the first comprehensive benchmarking study comparing traditional machine learning (ML), deep learning (DL), and large language model (LLM) approaches for mental health forecasting using the College Experience Sensing (CES) dataset, the most extensive longitudinal dataset of college student mental health to date. We systematically evaluate models across temporal windows, feature granularities, personalization strategies, and class imbalance handling. Our results show that DL models, particularly Transformer (Macro-F1 = 0.58), achieve the best overall performance, while LLMs show strength in contextual reasoning but weaker temporal modeling. Personalization substantially improves forecasts of severe mental health states. By revealing how different modeling approaches interpret phone sensing behavioral data over time, this work lays the groundwork for next-generation, adaptive, and human-centered mental health technologies that can advance both research and real-world well-being.
Unlocking Mental Health: Exploring College Students' Well-being through Smartphone Behaviors
Feb 12, 2025



The global mental health crisis is a pressing concern, with college students particularly vulnerable to rising mental health disorders. The widespread use of smartphones among young adults, while offering numerous benefits, has also been linked to negative outcomes such as addiction and regret, significantly impacting well-being. Leveraging the longest longitudinal dataset collected over four college years through passive mobile sensing, this study is the first to examine the relationship between students' smartphone unlocking behaviors and their mental health at scale in real-world settings. We provide the first evidence demonstrating the predictability of phone unlocking behaviors for mental health outcomes based on a large dataset, highlighting the potential of these novel features for future predictive models. Our findings reveal important variations in smartphone usage across genders and locations, offering a deeper understanding of the interplay between digital behaviors and mental health. We highlight future research directions aimed at mitigating adverse effects and promoting digital well-being in this population.
A Novel Feature Extraction Model for the Detection of Plant Disease from Leaf Images in Low Computational Devices
Oct 01, 2024Diseases in plants cause significant danger to productive and secure agriculture. Plant diseases can be detected early and accurately, reducing crop losses and pesticide use. Traditional methods of plant disease identification, on the other hand, are generally time-consuming and require professional expertise. It would be beneficial to the farmers if they could detect the disease quickly by taking images of the leaf directly. This will be a time-saving process and they can take remedial actions immediately. To achieve this a novel feature extraction approach for detecting tomato plant illnesses from leaf photos using low-cost computing systems such as mobile phones is proposed in this study. The proposed approach integrates various types of Deep Learning techniques to extract robust and discriminative features from leaf images. After the proposed feature extraction comparisons have been made on five cutting-edge deep learning models: AlexNet, ResNet50, VGG16, VGG19, and MobileNet. The dataset contains 10,000 leaf photos from ten classes of tomato illnesses and one class of healthy leaves. Experimental findings demonstrate that AlexNet has an accuracy score of 87%, with the benefit of being quick and lightweight, making it appropriate for use on embedded systems and other low-processing devices like smartphones.
On-Device Document Classification using multimodal features
Jan 06, 2021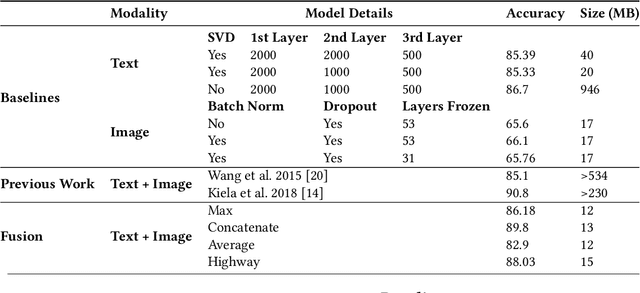
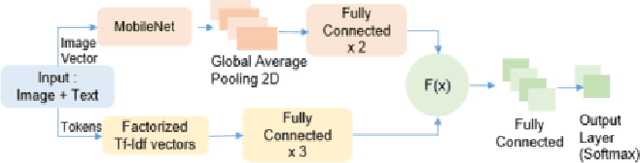
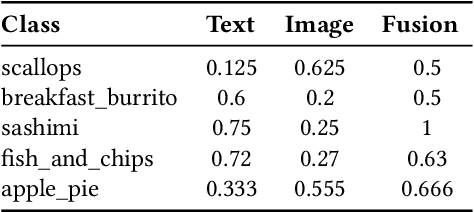
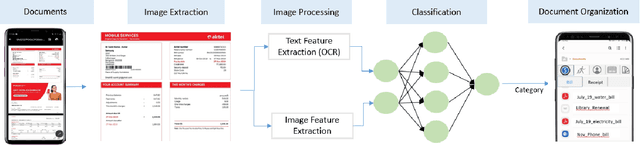
From small screenshots to large videos, documents take up a bulk of space in a modern smartphone. Documents in a phone can accumulate from various sources, and with the high storage capacity of mobiles, hundreds of documents are accumulated in a short period. However, searching or managing documents remains an onerous task, since most search methods depend on meta-information or only text in a document. In this paper, we showcase that a single modality is insufficient for classification and present a novel pipeline to classify documents on-device, thus preventing any private user data transfer to server. For this task, we integrate an open-source library for Optical Character Recognition (OCR) and our novel model architecture in the pipeline. We optimise the model for size, a necessary metric for on-device inference. We benchmark our classification model with a standard multimodal dataset FOOD-101 and showcase competitive results with the previous State of the Art with 30% model compression.
Real-time monitoring of driver drowsiness on mobile platforms using 3D neural networks
Oct 15, 2019

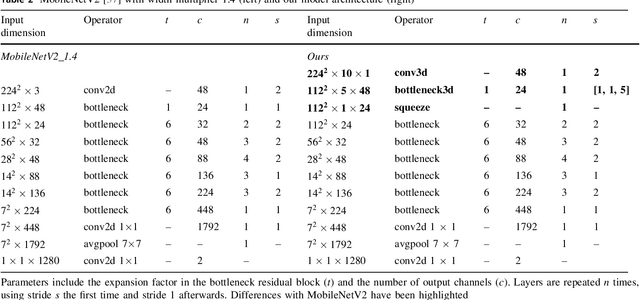
Driver drowsiness increases crash risk, leading to substantial road trauma each year. Drowsiness detection methods have received considerable attention, but few studies have investigated the implementation of a detection approach on a mobile phone. Phone applications reduce the need for specialised hardware and hence, enable a cost-effective roll-out of the technology across the driving population. While it has been shown that three-dimensional (3D) operations are more suitable for spatiotemporal feature learning, current methods for drowsiness detection commonly use frame-based, multi-step approaches. However, computationally expensive techniques that achieve superior results on action recognition benchmarks (e.g. 3D convolutions, optical flow extraction) create bottlenecks for real-time, safety-critical applications on mobile devices. Here, we show how depthwise separable 3D convolutions, combined with an early fusion of spatial and temporal information, can achieve a balance between high prediction accuracy and real-time inference requirements. In particular, increased accuracy is achieved when assessment requires motion information, for example, when sunglasses conceal the eyes. Further, a custom TensorFlow-based smartphone application shows the true impact of various approaches on inference times and demonstrates the effectiveness of real-time monitoring based on out-of-sample data to alert a drowsy driver. Our model is pre-trained on ImageNet and Kinetics and fine-tuned on a publicly available Driver Drowsiness Detection dataset. Fine-tuning on large naturalistic driving datasets could further improve accuracy to obtain robust in-vehicle performance. Overall, our research is a step towards practical deep learning applications, potentially preventing micro-sleeps and reducing road trauma.
* 13 pages, 2 figures, 'Online First' version. For associated mp4 files, see journal website
Towards Using Unlabeled Data in a Sparse-coding Framework for Human Activity Recognition
Jul 23, 2014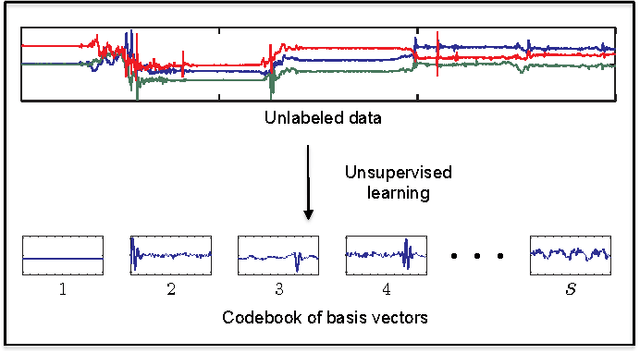

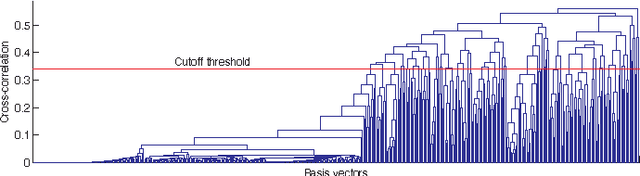

We propose a sparse-coding framework for activity recognition in ubiquitous and mobile computing that alleviates two fundamental problems of current supervised learning approaches. (i) It automatically derives a compact, sparse and meaningful feature representation of sensor data that does not rely on prior expert knowledge and generalizes extremely well across domain boundaries. (ii) It exploits unlabeled sample data for bootstrapping effective activity recognizers, i.e., substantially reduces the amount of ground truth annotation required for model estimation. Such unlabeled data is trivial to obtain, e.g., through contemporary smartphones carried by users as they go about their everyday activities. Based on the self-taught learning paradigm we automatically derive an over-complete set of basis vectors from unlabeled data that captures inherent patterns present within activity data. Through projecting raw sensor data onto the feature space defined by such over-complete sets of basis vectors effective feature extraction is pursued. Given these learned feature representations, classification backends are then trained using small amounts of labeled training data. We study the new approach in detail using two datasets which differ in terms of the recognition tasks and sensor modalities. Primarily we focus on transportation mode analysis task, a popular task in mobile-phone based sensing. The sparse-coding framework significantly outperforms the state-of-the-art in supervised learning approaches. Furthermore, we demonstrate the great practical potential of the new approach by successfully evaluating its generalization capabilities across both domain and sensor modalities by considering the popular Opportunity dataset. Our feature learning approach outperforms state-of-the-art approaches to analyzing activities in daily living.