 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMmptrack
Papers and Code
MCTR: Multi Camera Tracking Transformer
Aug 23, 2024



Multi-camera tracking plays a pivotal role in various real-world applications. While end-to-end methods have gained significant interest in single-camera tracking, multi-camera tracking remains predominantly reliant on heuristic techniques. In response to this gap, this paper introduces Multi-Camera Tracking tRansformer (MCTR), a novel end-to-end approach tailored for multi-object detection and tracking across multiple cameras with overlapping fields of view. MCTR leverages end-to-end detectors like DEtector TRansformer (DETR) to produce detections and detection embeddings independently for each camera view. The framework maintains set of track embeddings that encaplusate global information about the tracked objects, and updates them at every frame by integrating the local information from the view-specific detection embeddings. The track embeddings are probabilistically associated with detections in every camera view and frame to generate consistent object tracks. The soft probabilistic association facilitates the design of differentiable losses that enable end-to-end training of the entire system. To validate our approach, we conduct experiments on MMPTrack and AI City Challenge, two recently introduced large-scale multi-camera multi-object tracking datasets.
A Unified Multi-view Multi-person Tracking Framework
Feb 08, 2023Although there is a significant development in 3D Multi-view Multi-person Tracking (3D MM-Tracking), current 3D MM-Tracking frameworks are designed separately for footprint and pose tracking. Specifically, frameworks designed for footprint tracking cannot be utilized in 3D pose tracking, because they directly obtain 3D positions on the ground plane with a homography projection, which is inapplicable to 3D poses above the ground. In contrast, frameworks designed for pose tracking generally isolate multi-view and multi-frame associations and may not be robust to footprint tracking, since footprint tracking utilizes fewer key points than pose tracking, which weakens multi-view association cues in a single frame. This study presents a Unified Multi-view Multi-person Tracking framework to bridge the gap between footprint tracking and pose tracking. Without additional modifications, the framework can adopt monocular 2D bounding boxes and 2D poses as the input to produce robust 3D trajectories for multiple persons. Importantly, multi-frame and multi-view information are jointly employed to improve the performance of association and triangulation. The effectiveness of our framework is verified by accomplishing state-of-the-art performance on the Campus and Shelf datasets for 3D pose tracking, and by comparable results on the WILDTRACK and MMPTRACK datasets for 3D footprint tracking.
* Accepted to Computational Visual Media
MMPTRACK: Large-scale Densely Annotated Multi-camera Multiple People Tracking Benchmark
Nov 30, 2021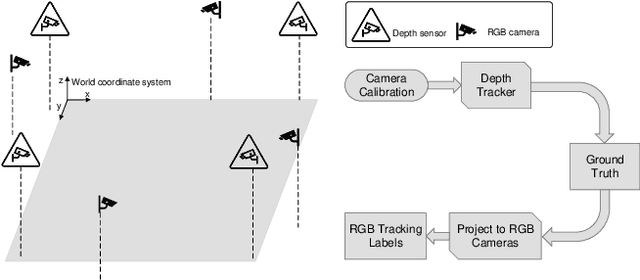
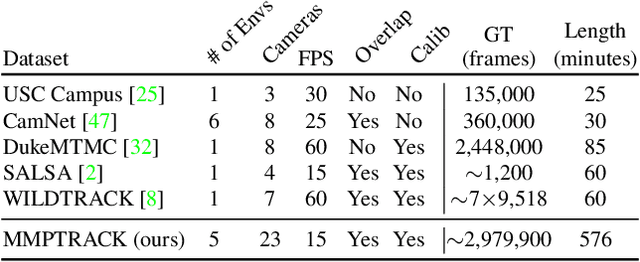

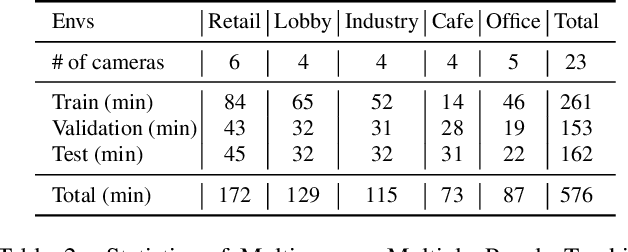
Multi-camera tracking systems are gaining popularity in applications that demand high-quality tracking results, such as frictionless checkout because monocular multi-object tracking (MOT) systems often fail in cluttered and crowded environments due to occlusion. Multiple highly overlapped cameras can significantly alleviate the problem by recovering partial 3D information. However, the cost of creating a high-quality multi-camera tracking dataset with diverse camera settings and backgrounds has limited the dataset scale in this domain. In this paper, we provide a large-scale densely-labeled multi-camera tracking dataset in five different environments with the help of an auto-annotation system. The system uses overlapped and calibrated depth and RGB cameras to build a high-performance 3D tracker that automatically generates the 3D tracking results. The 3D tracking results are projected to each RGB camera view using camera parameters to create 2D tracking results. Then, we manually check and correct the 3D tracking results to ensure the label quality, which is much cheaper than fully manual annotation. We have conducted extensive experiments using two real-time multi-camera trackers and a person re-identification (ReID) model with different settings. This dataset provides a more reliable benchmark of multi-camera, multi-object tracking systems in cluttered and crowded environments. Also, our results demonstrate that adapting the trackers and ReID models on this dataset significantly improves their performance. Our dataset will be publicly released upon the acceptance of this work.