 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImages Natural Scenes Ocr Data Of
Papers and Code
ViInfographicVQA: A Benchmark for Single and Multi-image Visual Question Answering on Vietnamese Infographics
Dec 13, 2025



Infographic Visual Question Answering (InfographicVQA) evaluates a model's ability to read and reason over data-rich, layout-heavy visuals that combine text, charts, icons, and design elements. Compared with scene-text or natural-image VQA, infographics require stronger integration of OCR, layout understanding, and numerical and semantic reasoning. We introduce ViInfographicVQA, the first benchmark for Vietnamese InfographicVQA, comprising over 6747 real-world infographics and 20409 human-verified question-answer pairs across economics, healthcare, education, and more. The benchmark includes two evaluation settings. The Single-image task follows the traditional setup in which each question is answered using a single infographic. The Multi-image task requires synthesizing evidence across multiple semantically related infographics and is, to our knowledge, the first Vietnamese evaluation of cross-image reasoning in VQA. We evaluate a range of recent vision-language models on this benchmark, revealing substantial performance disparities, with the most significant errors occurring on Multi-image questions that involve cross-image integration and non-span reasoning. ViInfographicVQA contributes benchmark results for Vietnamese InfographicVQA and sheds light on the limitations of current multimodal models in low-resource contexts, encouraging future exploration of layout-aware and cross-image reasoning methods.
GLYPH-SR: Can We Achieve Both High-Quality Image Super-Resolution and High-Fidelity Text Recovery via VLM-guided Latent Diffusion Model?
Oct 30, 2025Image super-resolution(SR) is fundamental to many vision system-from surveillance and autonomy to document analysis and retail analytics-because recovering high-frequency details, especially scene-text, enables reliable downstream perception. Scene-text, i.e., text embedded in natural images such as signs, product labels, and storefronts, often carries the most actionable information; when characters are blurred or hallucinated, optical character recognition(OCR) and subsequent decisions fail even if the rest of the image appears sharp. Yet previous SR research has often been tuned to distortion (PSNR/SSIM) or learned perceptual metrics (LIPIS, MANIQA, CLIP-IQA, MUSIQ) that are largely insensitive to character-level errors. Furthermore, studies that do address text SR often focus on simplified benchmarks with isolated characters, overlooking the challenges of text within complex natural scenes. As a result, scene-text is effectively treated as generic texture. For SR to be effective in practical deployments, it is therefore essential to explicitly optimize for both text legibility and perceptual quality. We present GLYPH-SR, a vision-language-guided diffusion framework that aims to achieve both objectives jointly. GLYPH-SR utilizes a Text-SR Fusion ControlNet(TS-ControlNet) guided by OCR data, and a ping-pong scheduler that alternates between text- and scene-centric guidance. To enable targeted text restoration, we train these components on a synthetic corpus while keeping the main SR branch frozen. Across SVT, SCUT-CTW1500, and CUTE80 at x4, and x8, GLYPH-SR improves OCR F1 by up to +15.18 percentage points over diffusion/GAN baseline (SVT x8, OpenOCR) while maintaining competitive MANIQA, CLIP-IQA, and MUSIQ. GLYPH-SR is designed to satisfy both objectives simultaneously-high readability and high visual realism-delivering SR that looks right and reds right.
ODM: A Text-Image Further Alignment Pre-training Approach for Scene Text Detection and Spotting
Mar 01, 2024



In recent years, text-image joint pre-training techniques have shown promising results in various tasks. However, in Optical Character Recognition (OCR) tasks, aligning text instances with their corresponding text regions in images poses a challenge, as it requires effective alignment between text and OCR-Text (referring to the text in images as OCR-Text to distinguish from the text in natural language) rather than a holistic understanding of the overall image content. In this paper, we propose a new pre-training method called OCR-Text Destylization Modeling (ODM) that transfers diverse styles of text found in images to a uniform style based on the text prompt. With ODM, we achieve better alignment between text and OCR-Text and enable pre-trained models to adapt to the complex and diverse styles of scene text detection and spotting tasks. Additionally, we have designed a new labeling generation method specifically for ODM and combined it with our proposed Text-Controller module to address the challenge of annotation costs in OCR tasks, allowing a larger amount of unlabeled data to participate in pre-training. Extensive experiments on multiple public datasets demonstrate that our method significantly improves performance and outperforms current pre-training methods in scene text detection and spotting tasks. Code is available at {https://github.com/PriNing/ODM}.
Efficient, Lexicon-Free OCR using Deep Learning
Jun 05, 2019
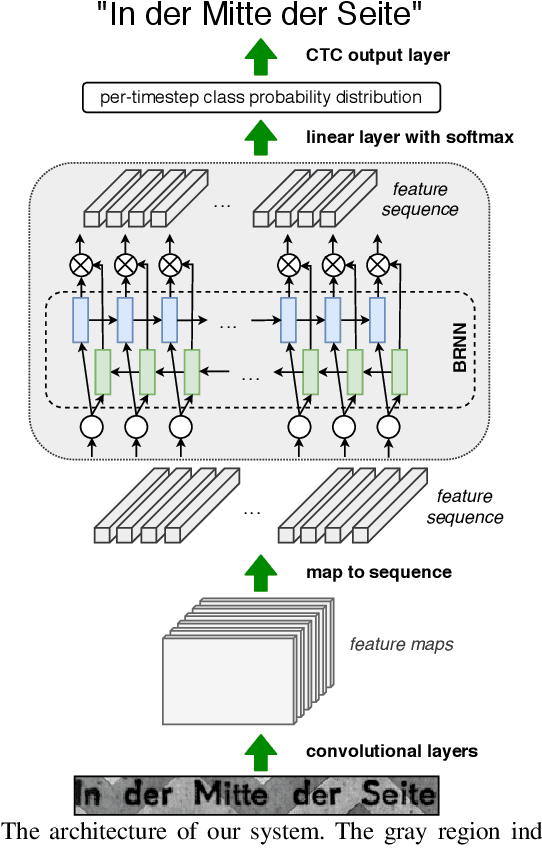
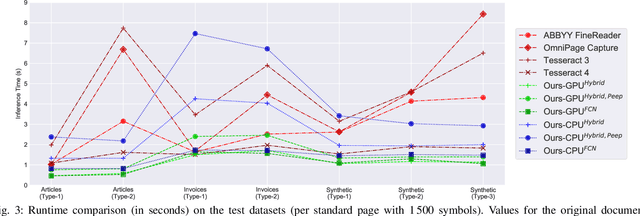
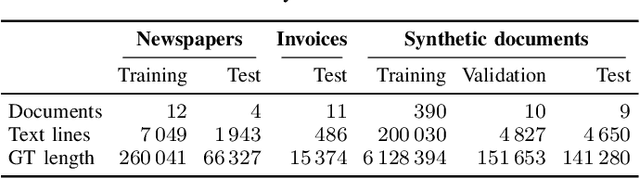
Contrary to popular belief, Optical Character Recognition (OCR) remains a challenging problem when text occurs in unconstrained environments, like natural scenes, due to geometrical distortions, complex backgrounds, and diverse fonts. In this paper, we present a segmentation-free OCR system that combines deep learning methods, synthetic training data generation, and data augmentation techniques. We render synthetic training data using large text corpora and over 2000 fonts. To simulate text occurring in complex natural scenes, we augment extracted samples with geometric distortions and with a proposed data augmentation technique - alpha-compositing with background textures. Our models employ a convolutional neural network encoder to extract features from text images. Inspired by the recent progress in neural machine translation and language modeling, we examine the capabilities of both recurrent and convolutional neural networks in modeling the interactions between input elements.
Text Recognition in Scene Image and Video Frame using Color Channel Selection
Jul 27, 2017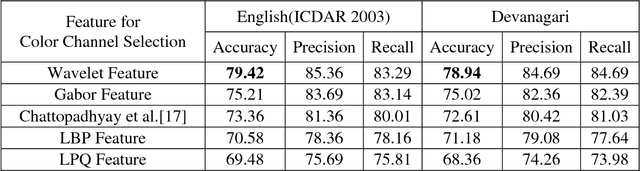
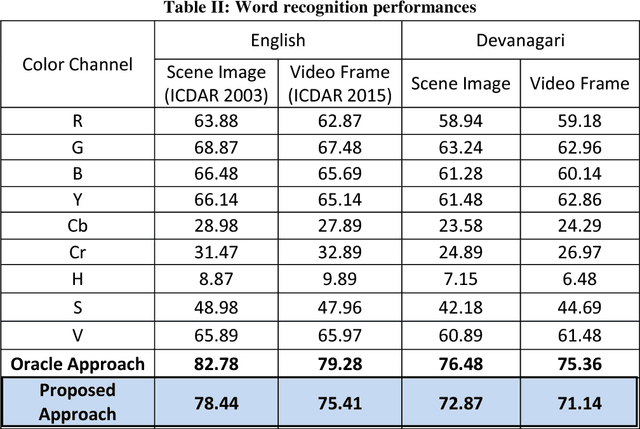
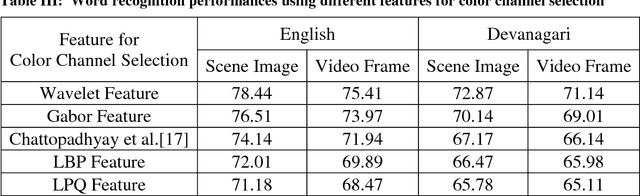
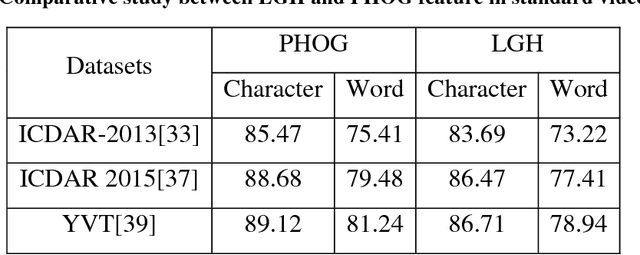
In recent years, recognition of text from natural scene image and video frame has got increased attention among the researchers due to its various complexities and challenges. Because of low resolution, blurring effect, complex background, different fonts, color and variant alignment of text within images and video frames, etc., text recognition in such scenario is difficult. Most of the current approaches usually apply a binarization algorithm to convert them into binary images and next OCR is applied to get the recognition result. In this paper, we present a novel approach based on color channel selection for text recognition from scene images and video frames. In the approach, at first, a color channel is automatically selected and then selected color channel is considered for text recognition. Our text recognition framework is based on Hidden Markov Model (HMM) which uses Pyramidal Histogram of Oriented Gradient features extracted from selected color channel. From each sliding window of a color channel our color-channel selection approach analyzes the image properties from the sliding window and then a multi-label Support Vector Machine (SVM) classifier is applied to select the color channel that will provide the best recognition results in the sliding window. This color channel selection for each sliding window has been found to be more fruitful than considering a single color channel for the whole word image. Five different features have been analyzed for multi-label SVM based color channel selection where wavelet transform based feature outperforms others. Our framework has been tested on different publicly available scene/video text image datasets. For Devanagari script, we collected our own data dataset. The performances obtained from experimental results are encouraging and show the advantage of the proposed method.