 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIiit Ar 13k
Papers and Code
RanLayNet: A Dataset for Document Layout Detection used for Domain Adaptation and Generalization
Apr 15, 2024



Large ground-truth datasets and recent advances in deep learning techniques have been useful for layout detection. However, because of the restricted layout diversity of these datasets, training on them requires a sizable number of annotated instances, which is both expensive and time-consuming. As a result, differences between the source and target domains may significantly impact how well these models function. To solve this problem, domain adaptation approaches have been developed that use a small quantity of labeled data to adjust the model to the target domain. In this research, we introduced a synthetic document dataset called RanLayNet, enriched with automatically assigned labels denoting spatial positions, ranges, and types of layout elements. The primary aim of this endeavor is to develop a versatile dataset capable of training models with robustness and adaptability to diverse document formats. Through empirical experimentation, we demonstrate that a deep layout identification model trained on our dataset exhibits enhanced performance compared to a model trained solely on actual documents. Moreover, we conduct a comparative analysis by fine-tuning inference models using both PubLayNet and IIIT-AR-13K datasets on the Doclaynet dataset. Our findings emphasize that models enriched with our dataset are optimal for tasks such as achieving 0.398 and 0.588 mAP95 score in the scientific document domain for the TABLE class.
Semantic Table Detection with LayoutLMv3
Nov 25, 2022

This paper presents an application of the LayoutLMv3 model for semantic table detection on financial documents from the IIIT-AR-13K dataset. The motivation behind this paper's experiment was that LayoutLMv3's official paper had no results for table detection using semantic information. We concluded that our approach did not improve the model's table detection capabilities, for which we can give several possible reasons. Either the model's weights were unsuitable for our purpose, or we needed to invest more time in optimising the model's hyperparameters. It is also possible that semantic information does not improve a model's table detection accuracy.
Robust Table Detection and Structure Recognition from Heterogeneous Document Images
Mar 17, 2022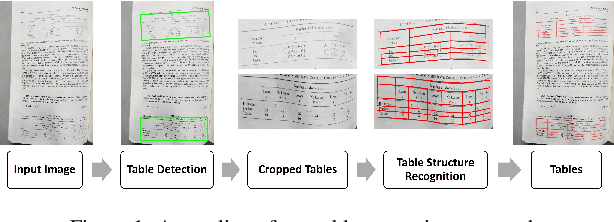
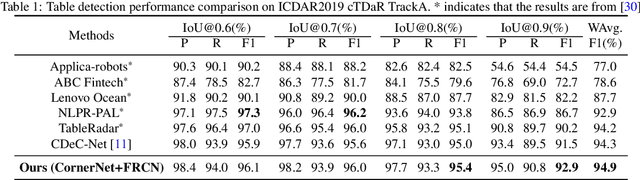
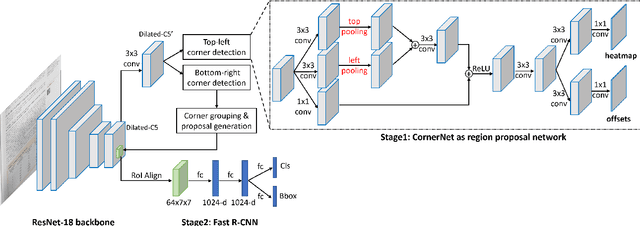

We introduce a new table detection and structure recognition approach named RobusTabNet to detect the boundaries of tables and reconstruct the cellular structure of the table from heterogeneous document images. For table detection, we propose to use CornerNet as a new region proposal network to generate higher quality table proposals for Faster R-CNN, which has significantly improved the localization accuracy of Faster R-CNN for table detection. Consequently, our table detection approach achieves state-of-the-art performance on three public table detection benchmarks, namely cTDaR TrackA, PubLayNet and IIIT-AR-13K, by only using a lightweight ResNet-18 backbone network. Furthermore, we propose a new split-and-merge based table structure recognition approach, in which a novel spatial CNN based separation line prediction module is proposed to split each detected table into a grid of cells, and a Grid CNN based cell merging module is applied to recover the spanning cells. As the spatial CNN module can effectively propagate contextual information across the whole table image, our table structure recognizer can robustly recognize tables with large blank spaces and geometrically distorted (even curved) tables. Thanks to these two techniques, our table structure recognition approach achieves state-of-the-art performance on three public benchmarks, including SciTSR, PubTabNet and cTDaR TrackB. Moreover, we have further demonstrated the advantages of our approach in recognizing tables with complex structures, large blank spaces, empty or spanning cells as well as geometrically distorted or even curved tables on a more challenging in-house dataset.
IIIT-AR-13K: A New Dataset for Graphical Object Detection in Documents
Aug 06, 2020
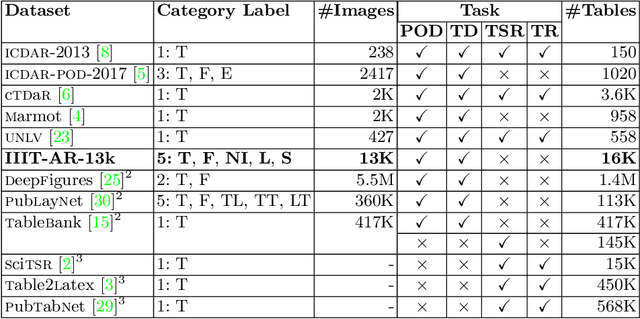

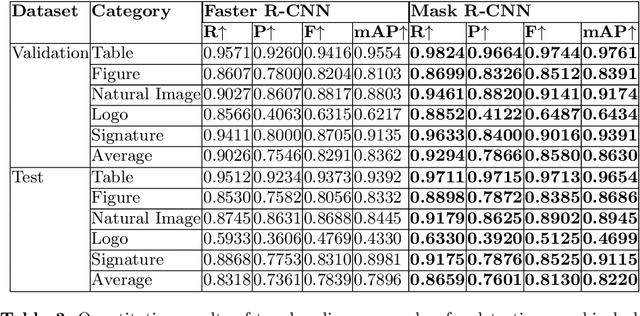
We introduce a new dataset for graphical object detection in business documents, more specifically annual reports. This dataset, IIIT-AR-13k, is created by manually annotating the bounding boxes of graphical or page objects in publicly available annual reports. This dataset contains a total of 13k annotated page images with objects in five different popular categories - table, figure, natural image, logo, and signature. It is the largest manually annotated dataset for graphical object detection. Annual reports created in multiple languages for several years from various companies bring high diversity into this dataset. We benchmark IIIT-AR-13K dataset with two state of the art graphical object detection techniques using Faster R-CNN [20] and Mask R-CNN [11] and establish high baselines for further research. Our dataset is highly effective as training data for developing practical solutions for graphical object detection in both business documents and technical articles. By training with IIIT-AR-13K, we demonstrate the feasibility of a single solution that can report superior performance compared to the equivalent ones trained with a much larger amount of data, for table detection. We hope that our dataset helps in advancing the research for detecting various types of graphical objects in business documents.
* 15 pages, DAS 2020