 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglalekhaimagecaptions
Papers and Code
Bangla Image Caption Generation through CNN-Transformer based Encoder-Decoder Network
Oct 24, 2021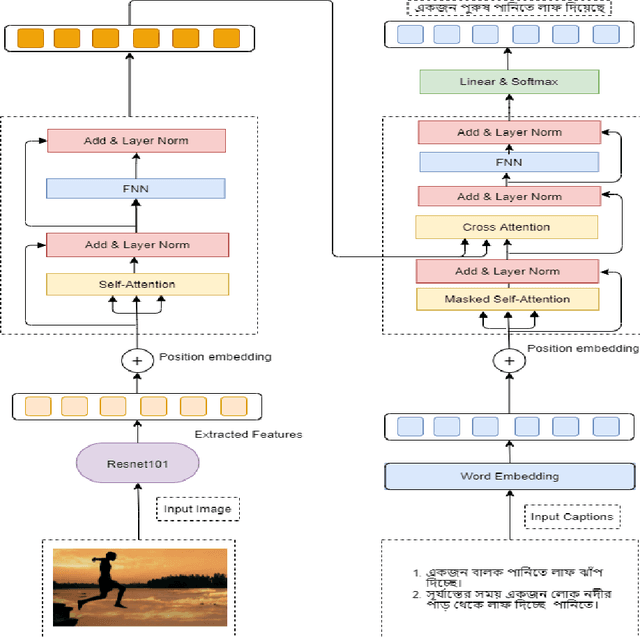

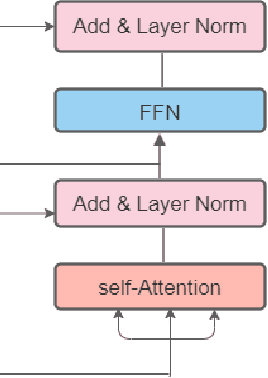
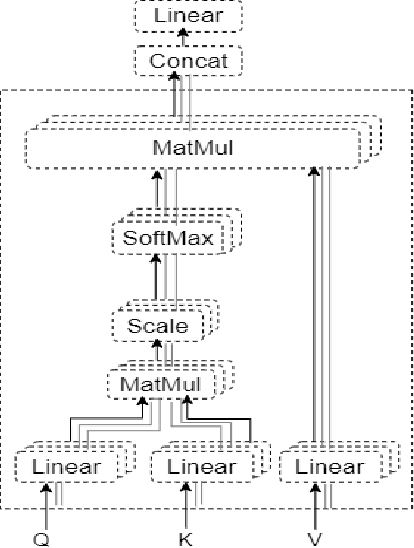
Automatic Image Captioning is the never-ending effort of creating syntactically and validating the accuracy of textual descriptions of an image in natural language with context. The encoder-decoder structure used throughout existing Bengali Image Captioning (BIC) research utilized abstract image feature vectors as the encoder's input. We propose a novel transformer-based architecture with an attention mechanism with a pre-trained ResNet-101 model image encoder for feature extraction from images. Experiments demonstrate that the language decoder in our technique captures fine-grained information in the caption and, then paired with image features, produces accurate and diverse captions on the BanglaLekhaImageCaptions dataset. Our approach outperforms all existing Bengali Image Captioning work and sets a new benchmark by scoring 0.694 on BLEU-1, 0.630 on BLEU-2, 0.582 on BLEU-3, and 0.337 on METEOR.
Improved Bengali Image Captioning via deep convolutional neural network based encoder-decoder model
Feb 14, 2021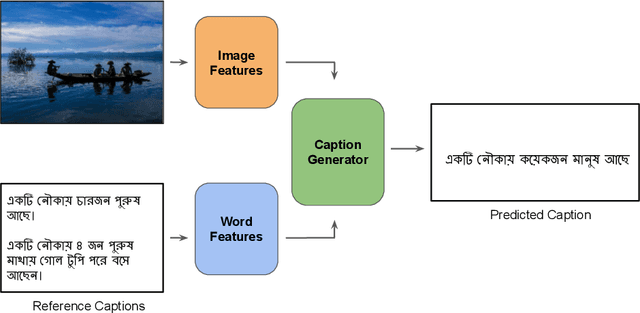
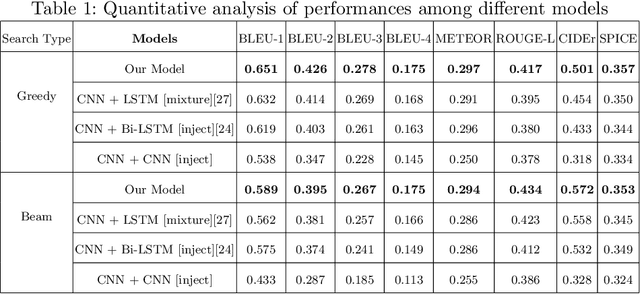
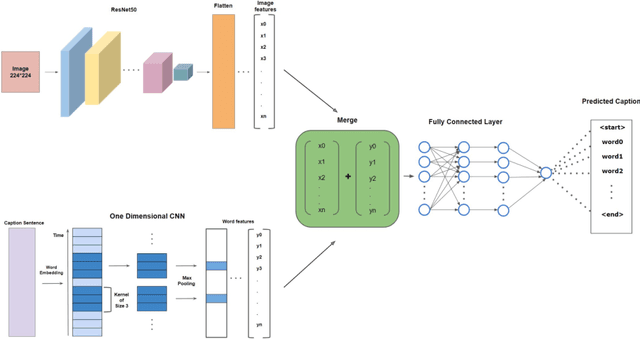

Image Captioning is an arduous task of producing syntactically and semantically correct textual descriptions of an image in natural language with context related to the image. Existing notable pieces of research in Bengali Image Captioning (BIC) are based on encoder-decoder architecture. This paper presents an end-to-end image captioning system utilizing a multimodal architecture by combining a one-dimensional convolutional neural network (CNN) to encode sequence information with a pre-trained ResNet-50 model image encoder for extracting region-based visual features. We investigate our approach's performance on the BanglaLekhaImageCaptions dataset using the existing evaluation metrics and perform a human evaluation for qualitative analysis. Experiments show that our approach's language encoder captures the fine-grained information in the caption, and combined with the image features, it generates accurate and diversified caption. Our work outperforms all the existing BIC works and achieves a new state-of-the-art (SOTA) performance by scoring 0.651 on BLUE-1, 0.572 on CIDEr, 0.297 on METEOR, 0.434 on ROUGE, and 0.357 on SPICE.
TextMage: The Automated Bangla Caption Generator Based On Deep Learning
Oct 15, 2020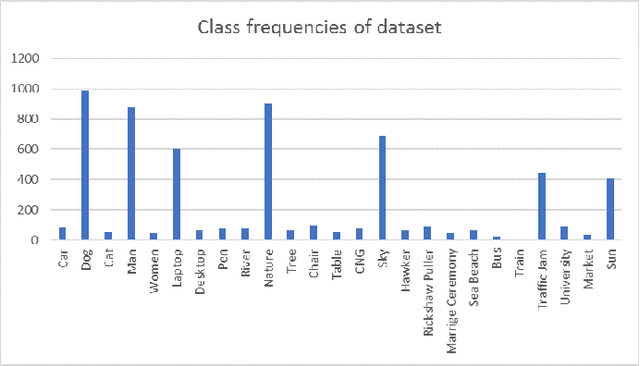
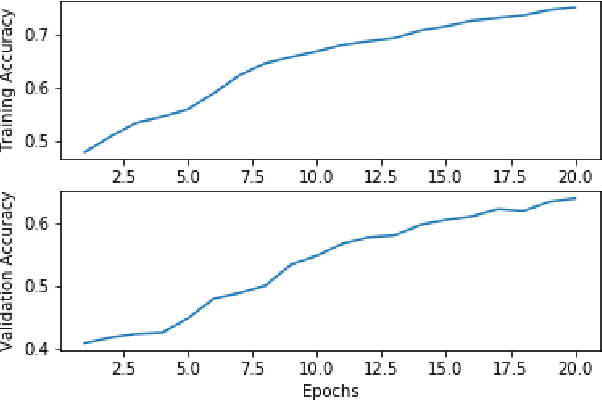
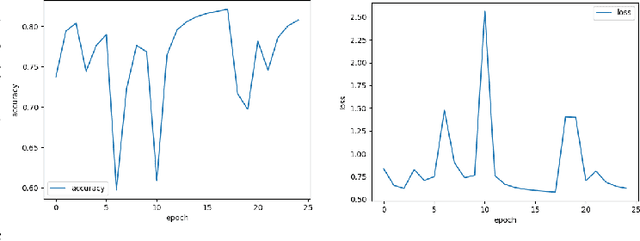
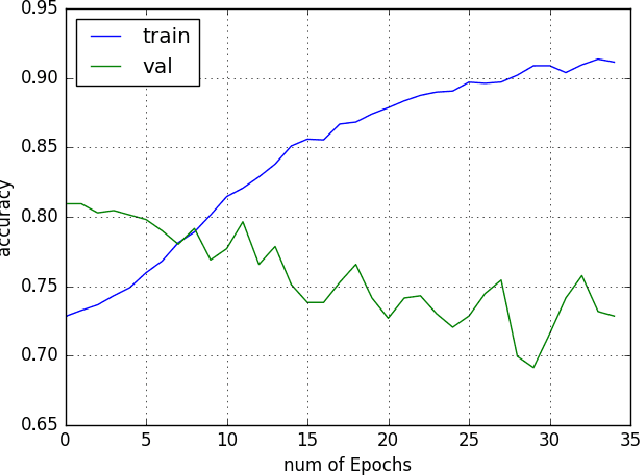
Neural Networks and Deep Learning have seen an upsurge of research in the past decade due to the improved results. Generates text from the given image is a crucial task that requires the combination of both sectors which are computer vision and natural language processing in order to understand an image and represent it using a natural language. However existing works have all been done on a particular lingual domain and on the same set of data. This leads to the systems being developed to perform poorly on images that belong to specific locales' geographical context. TextMage is a system that is capable of understanding visual scenes that belong to the Bangladeshi geographical context and use its knowledge to represent what it understands in Bengali. Hence, we have trained a model on our previously developed and published dataset named BanglaLekhaImageCaptions. This dataset contains 9,154 images along with two annotations for each image. In order to access performance, the proposed model has been implemented and evaluated.