 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTLA: Vision-Tactile-Language-Action Model with Preference Learning for Insertion Manipulation
Paper and Code
May 14, 2025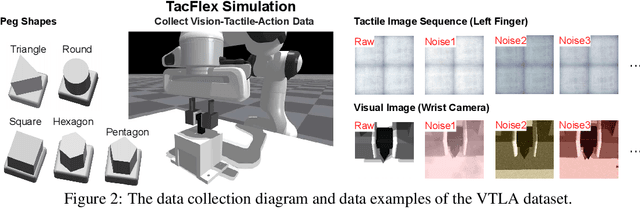



While vision-language models have advanced significantly, their application in language-conditioned robotic manipulation is still underexplored, especially for contact-rich tasks that extend beyond visually dominant pick-and-place scenarios. To bridge this gap, we introduce Vision-Tactile-Language-Action model, a novel framework that enables robust policy generation in contact-intensive scenarios by effectively integrating visual and tactile inputs through cross-modal language grounding. A low-cost, multi-modal dataset has been constructed in a simulation environment, containing vision-tactile-action-instruction pairs specifically designed for the fingertip insertion task. Furthermore, we introduce Direct Preference Optimization (DPO) to offer regression-like supervision for the VTLA model, effectively bridging the gap between classification-based next token prediction loss and continuous robotic tasks. Experimental results show that the VTLA model outperforms traditional imitation learning methods (e.g., diffusion policies) and existing multi-modal baselines (TLA/VLA), achieving over 90% success rates on unseen peg shapes. Finally, we conduct real-world peg-in-hole experiments to demonstrate the exceptional Sim2Real performance of the proposed VTLA model. For supplementary videos and results, please visit our project website: https://sites.google.com/view/vtla