 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentional Graph Convolutional Network for Structure-aware Audio-Visual Scene Classification
Paper and Code
Dec 31, 2022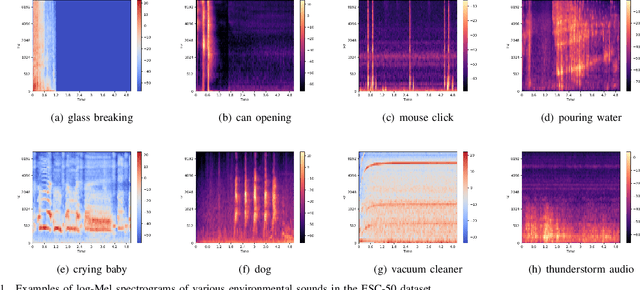
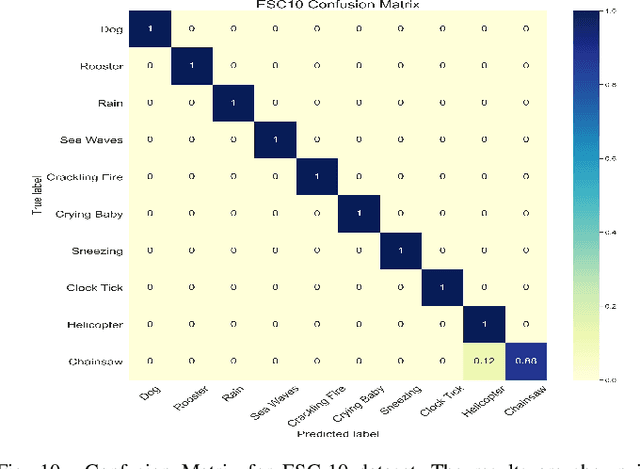
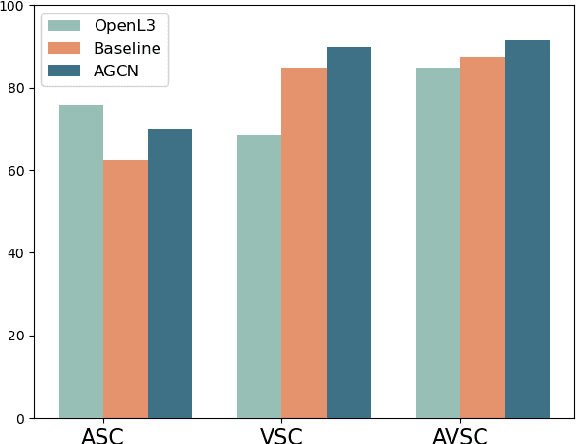
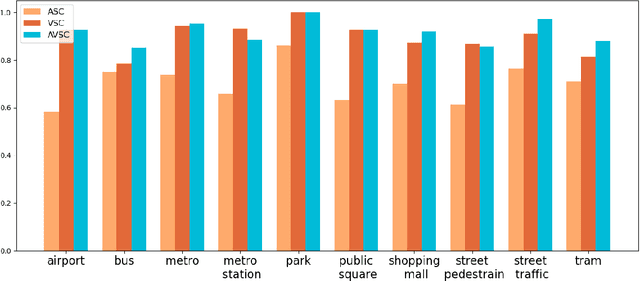
Audio-Visual scene understanding is a challenging problem due to the unstructured spatial-temporal relations that exist in the audio signals and spatial layouts of different objects and various texture patterns in the visual images. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of explicit semantically relevant frames of sound signals and visual images has been overlooked. To this end, we present an end-to-end framework, namely attentional graph convolutional network (AGCN), for structure-aware audio-visual scene representation. First, the spectrogram of sound and input image is processed by a backbone network for feature extraction. Then, to build multi-scale hierarchical information of input features, we utilize an attention fusion mechanism to aggregate features from multiple layers of the backbone network. Notably, to well represent the salient regions and contextual information of audio-visual inputs, the salient acoustic graph (SAG) and contextual acoustic graph (CAG), salient visual graph (SVG), and contextual visual graph (CVG) are constructed for the audio-visual scene representation. Finally, the constructed graphs pass through a graph convolutional network for structure-aware audio-visual scene recognition. Extensive experimental results on the audio, visual and audio-visual scene recognition datasets show that promising results have been achieved by the AGCN methods. Visualizing graphs on the spectrograms and images have been presented to show the effectiveness of proposed CAG/SAG and CVG/SVG that could focus on the salient and semantic relevant regions.