 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMO: Masked Multimodal Modeling for Fine-Grained Vision-Language Representation Learning
Paper and Code
Oct 09, 2022
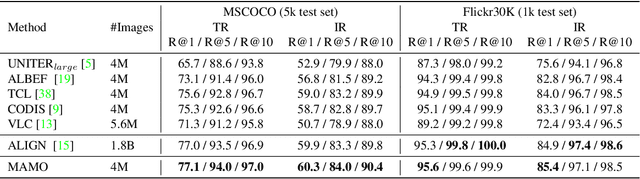
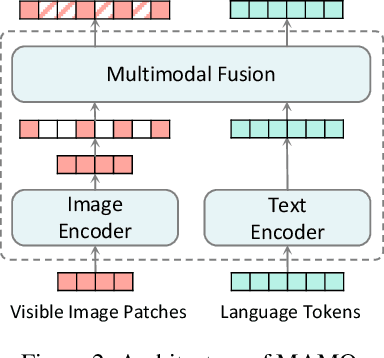
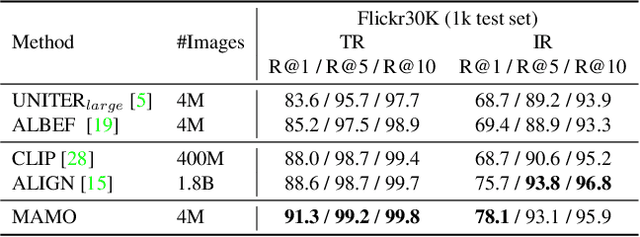
Multimodal representation learning has shown promising improvements on various vision-language tasks. Most existing methods excel at building global-level alignment between vision and language while lacking effective fine-grained image-text interaction. In this paper, we propose a jointly masked multimodal modeling method to learn fine-grained multimodal representations. Our method performs joint masking on image-text input and integrates both implicit and explicit targets for the masked signals to recover. The implicit target provides a unified and debiased objective for vision and language, where the model predicts latent multimodal representations of the unmasked input. The explicit target further enriches the multimodal representations by recovering high-level and semantically meaningful information: momentum visual features of image patches and concepts of word tokens. Through such a masked modeling process, our model not only learns fine-grained multimodal interaction, but also avoids the semantic gap between high-level representations and low- or mid-level prediction targets (e.g. image pixels), thus producing semantically rich multimodal representations that perform well on both zero-shot and fine-tuned settings. Our pre-trained model (named MAMO) achieves state-of-the-art performance on various downstream vision-language tasks, including image-text retrieval, visual question answering, visual reasoning, and weakly-supervised visual grounding.