 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffsound: Discrete Diffusion Model for Text-to-sound Generation
Paper and Code
Jul 20, 2022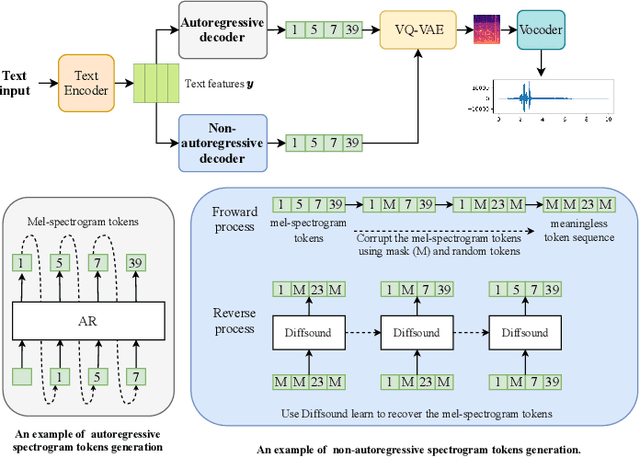
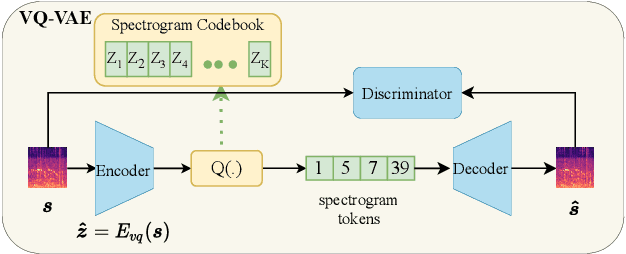
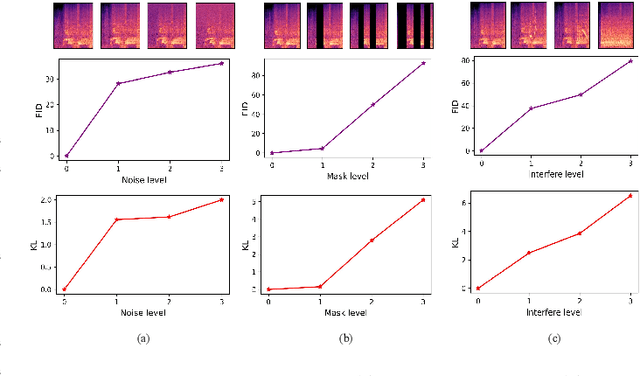

Generating sound effects that humans want is an important topic. However, there are few studies in this area for sound generation. In this study, we investigate generating sound conditioned on a text prompt and propose a novel text-to-sound generation framework that consists of a text encoder, a Vector Quantized Variational Autoencoder (VQ-VAE), a decoder, and a vocoder. The framework first uses the decoder to transfer the text features extracted from the text encoder to a mel-spectrogram with the help of VQ-VAE, and then the vocoder is used to transform the generated mel-spectrogram into a waveform. We found that the decoder significantly influences the generation performance. Thus, we focus on designing a good decoder in this study. We begin with the traditional autoregressive decoder, which has been proved as a state-of-the-art method in previous sound generation works. However, the AR decoder always predicts the mel-spectrogram tokens one by one in order, which introduces the unidirectional bias and accumulation of errors problems. Moreover, with the AR decoder, the sound generation time increases linearly with the sound duration. To overcome the shortcomings introduced by AR decoders, we propose a non-autoregressive decoder based on the discrete diffusion model, named Diffsound. Specifically, the Diffsound predicts all of the mel-spectrogram tokens in one step and then refines the predicted tokens in the next step, so the best-predicted results can be obtained after several steps. Our experiments show that our proposed Diffsound not only produces better text-to-sound generation results when compared with the AR decoder but also has a faster generation speed, e.g., MOS: 3.56 \textit{v.s} 2.786, and the generation speed is five times faster than the AR decoder.