 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Score Based Conformer Speaker Adaptation for Speech Recognition
Paper and Code
Jun 24, 2022
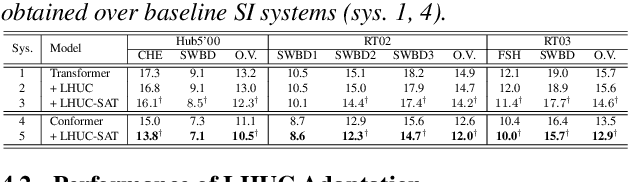
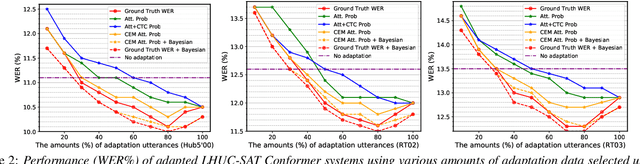

A key challenge for automatic speech recognition (ASR) systems is to model the speaker level variability. In this paper, compact speaker dependent learning hidden unit contributions (LHUC) are used to facilitate both speaker adaptive training (SAT) and test time unsupervised speaker adaptation for state-of-the-art Conformer based end-to-end ASR systems. The sensitivity during adaptation to supervision error rate is reduced using confidence score based selection of the more "trustworthy" subset of speaker specific data. A confidence estimation module is used to smooth the over-confident Conformer decoder output probabilities before serving as confidence scores. The increased data sparsity due to speaker level data selection is addressed using Bayesian estimation of LHUC parameters. Experiments on the 300-hour Switchboard corpus suggest that the proposed LHUC-SAT Conformer with confidence score based test time unsupervised adaptation outperformed the baseline speaker independent and i-vector adapted Conformer systems by up to 1.0%, 1.0%, and 1.2% absolute (9.0%, 7.9%, and 8.9% relative) word error rate (WER) reductions on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Consistent performance improvements were retained after external Transformer and LSTM language models were used for rescoring.