 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-based Object-centric Transformers for Efficient Video Generation
Paper and Code

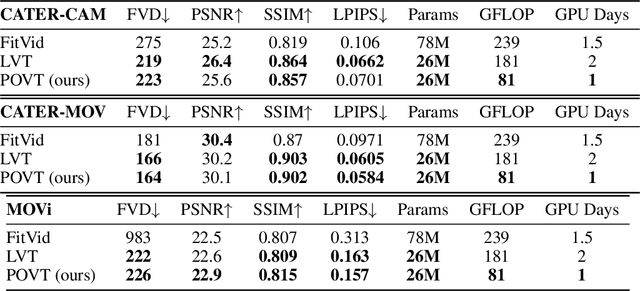
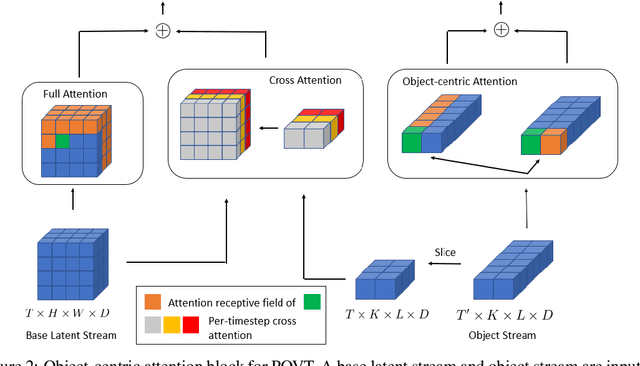

In this work, we present Patch-based Object-centric Video Transformer (POVT), a novel region-based video generation architecture that leverages object-centric information to efficiently model temporal dynamics in videos. We build upon prior work in video prediction via an autoregressive transformer over the discrete latent space of compressed videos, with an added modification to model object-centric information via bounding boxes. Due to better compressibility of object-centric representations, we can improve training efficiency by allowing the model to only access object information for longer horizon temporal information. When evaluated on various difficult object-centric datasets, our method achieves better or equal performance to other video generation models, while remaining computationally more efficient and scalable. In addition, we show that our method is able to perform object-centric controllability through bounding box manipulation, which may aid downstream tasks such as video editing, or visual planning. Samples are available at https://sites.google.com/view/povt-public