 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2S2: Encoding-Enhanced Sequence-to-Sequence Pretraining for Language Understanding and Generation
Paper and Code
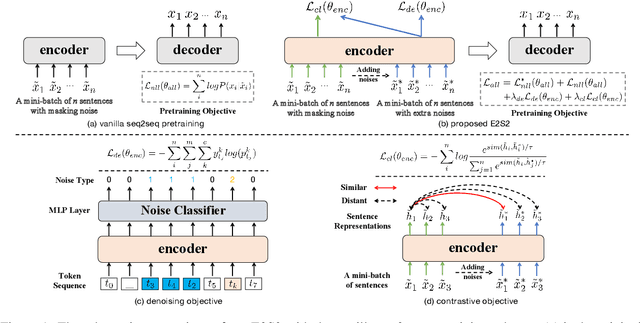
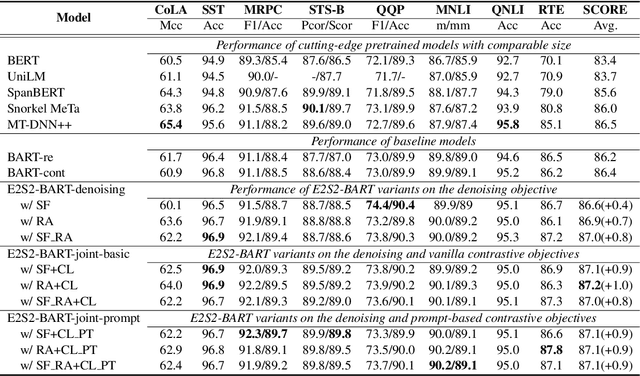
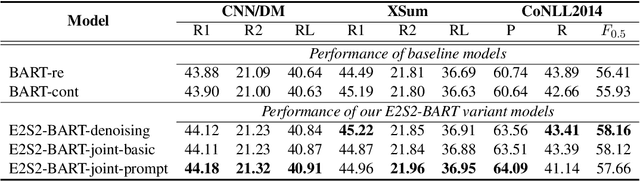
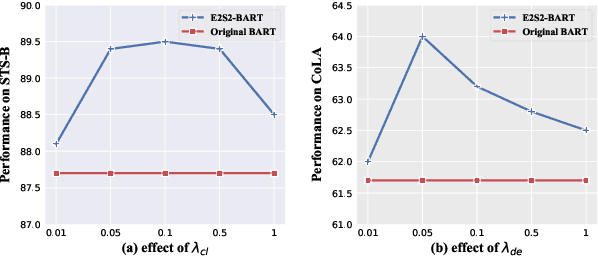
Sequence-to-sequence (seq2seq) learning has become a popular trend for pretraining language models, due to its succinct and universal framework. However, the prior seq2seq pretraining models generally focus on reconstructive objectives on the decoder side and neglect the effect of encoder-side supervisions, which may lead to sub-optimal performance. To this end, we propose an encoding-enhanced seq2seq pretraining strategy, namely E2S2, which improves the seq2seq models via integrating more efficient self-supervised information into the encoders. Specifically, E2S2 contains two self-supervised objectives upon the encoder, which are from two perspectives: 1) denoising the corrupted sentence (denoising objective); 2) learning robust sentence representations (contrastive objective). With these two objectives, the encoder can effectively distinguish the noise tokens and capture more syntactic and semantic knowledge, thus strengthening the ability of seq2seq model to comprehend the input sentence and conditionally generate the target. We conduct extensive experiments spanning language understanding and generation tasks upon the state-of-the-art seq2seq pretrained language model BART. We show that E2S2 can consistently boost the performance, including 1.0% averaged gain on GLUE benchmark and 1.75% F_0.5 score improvement on CoNLL2014 dataset, validating the effectiveness and robustness of our E2S2.