 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBA: A Tuning-free Approach to Switch between Synchronous and Asynchronous Training for Recommendation Model
Paper and Code
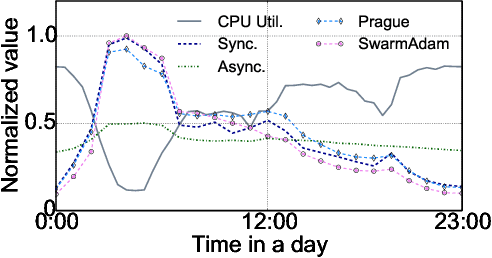
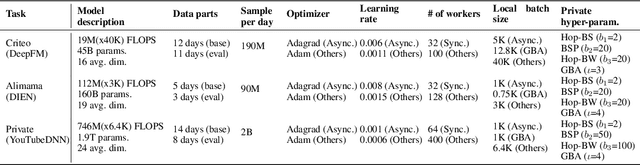
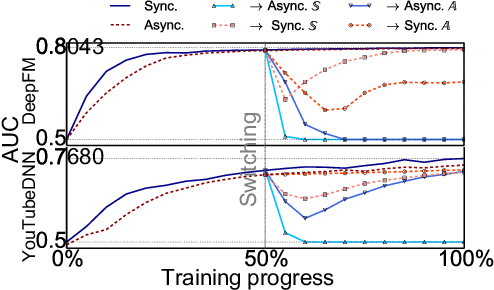

High-concurrency asynchronous training upon parameter server (PS) architecture and high-performance synchronous training upon all-reduce (AR) architecture are the most commonly deployed distributed training modes for recommender systems. Although the synchronous AR training is designed to have higher training efficiency, the asynchronous PS training would be a better choice on training speed when there are stragglers (slow workers) in the shared cluster, especially under limited computing resources. To take full advantages of these two training modes, an ideal way is to switch between them upon the cluster status. We find two obstacles to a tuning-free approach: the different distribution of the gradient values and the stale gradients from the stragglers. In this paper, we propose Global Batch gradients Aggregation (GBA) over PS, which aggregates and applies gradients with the same global batch size as the synchronous training. A token-control process is implemented to assemble the gradients and decay the gradients with severe staleness. We provide the convergence analysis to demonstrate the robustness of GBA over the recommendation models against the gradient staleness. Experiments on three industrial-scale recommendation tasks show that GBA is an effective tuning-free approach for switching. Compared to the state-of-the-art derived asynchronous training, GBA achieves up to 0.2% improvement on the AUC metric, which is significant for the recommendation models. Meanwhile, under the strained hardware resource, GBA speeds up at least 2.4x compared to the synchronous training.