 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Applicable Reinforcement Learning: Improving the Generalization and Sample Efficiency with Policy Ensemble
Paper and Code
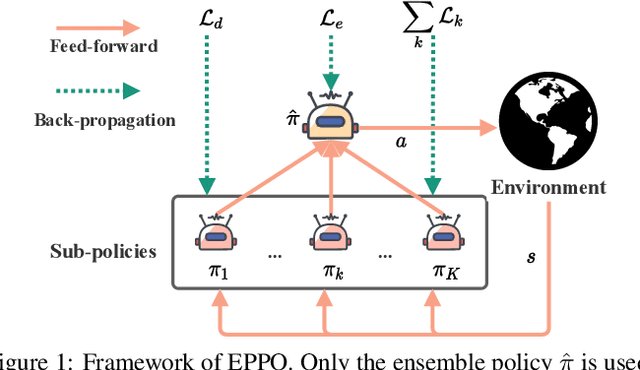
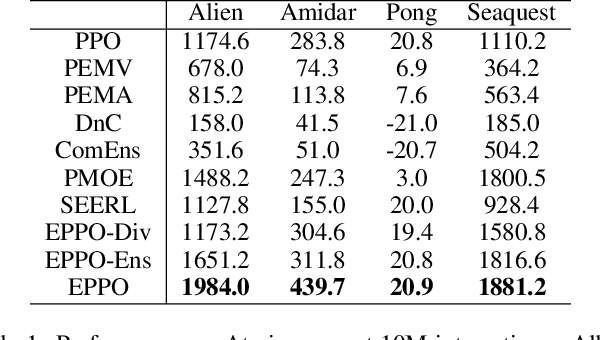
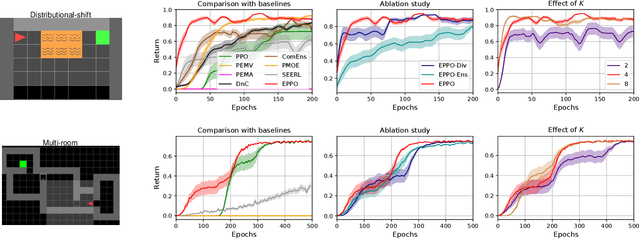
It is challenging for reinforcement learning (RL) algorithms to succeed in real-world applications like financial trading and logistic system due to the noisy observation and environment shifting between training and evaluation. Thus, it requires both high sample efficiency and generalization for resolving real-world tasks. However, directly applying typical RL algorithms can lead to poor performance in such scenarios. Considering the great performance of ensemble methods on both accuracy and generalization in supervised learning (SL), we design a robust and applicable method named Ensemble Proximal Policy Optimization (EPPO), which learns ensemble policies in an end-to-end manner. Notably, EPPO combines each policy and the policy ensemble organically and optimizes both simultaneously. In addition, EPPO adopts a diversity enhancement regularization over the policy space which helps to generalize to unseen states and promotes exploration. We theoretically prove EPPO increases exploration efficacy, and through comprehensive experimental evaluations on various tasks, we demonstrate that EPPO achieves higher efficiency and is robust for real-world applications compared with vanilla policy optimization algorithms and other ensemble methods. Code and supplemental materials are available at https://seqml.github.io/eppo.