 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint learning of object graph and relation graph for visual question answering
Paper and Code
May 09, 2022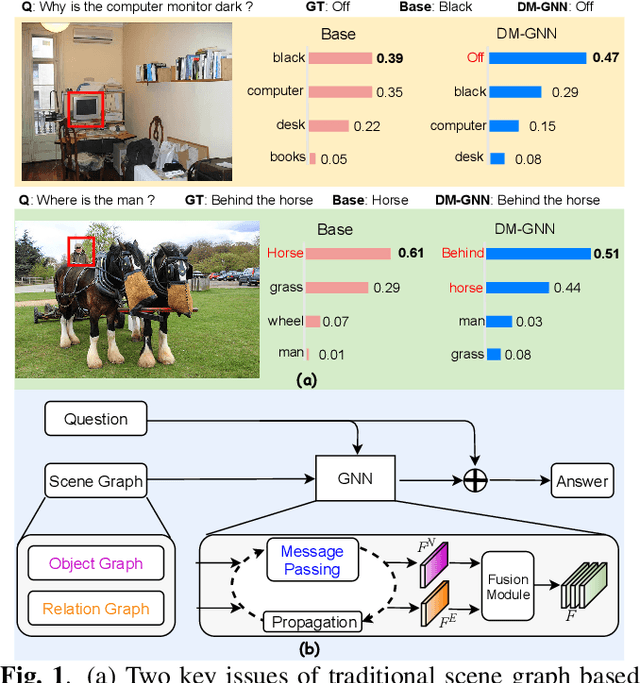
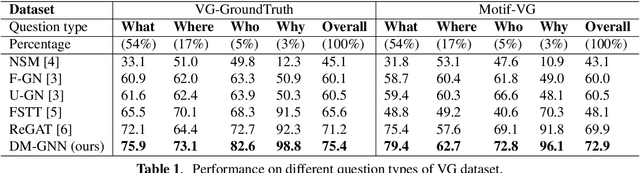
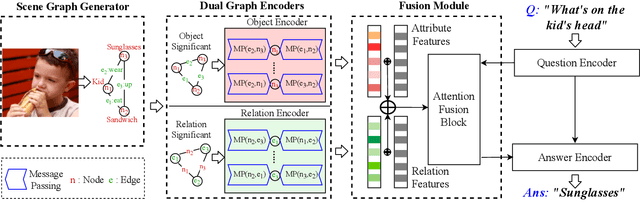
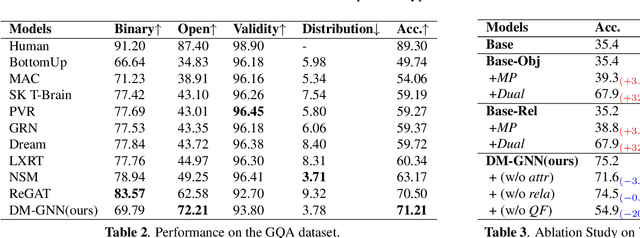
Modeling visual question answering(VQA) through scene graphs can significantly improve the reasoning accuracy and interpretability. However, existing models answer poorly for complex reasoning questions with attributes or relations, which causes false attribute selection or missing relation in Figure 1(a). It is because these models cannot balance all kinds of information in scene graphs, neglecting relation and attribute information. In this paper, we introduce a novel Dual Message-passing enhanced Graph Neural Network (DM-GNN), which can obtain a balanced representation by properly encoding multi-scale scene graph information. Specifically, we (i)transform the scene graph into two graphs with diversified focuses on objects and relations; Then we design a dual structure to encode them, which increases the weights from relations (ii)fuse the encoder output with attribute features, which increases the weights from attributes; (iii)propose a message-passing mechanism to enhance the information transfer between objects, relations and attributes. We conduct extensive experiments on datasets including GQA, VG, motif-VG and achieve new state of the art.