 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-Matting: High-Accuracy Natural Image Matting
Paper and Code

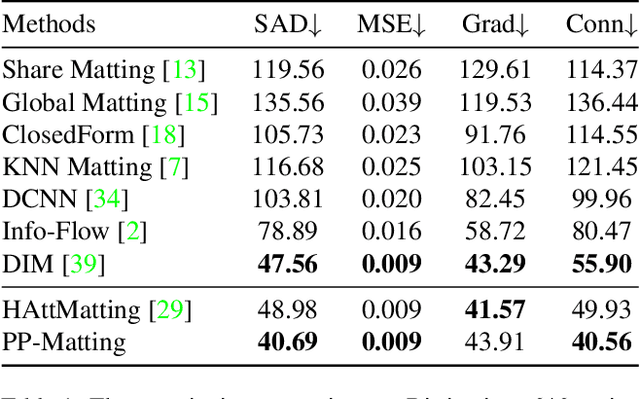
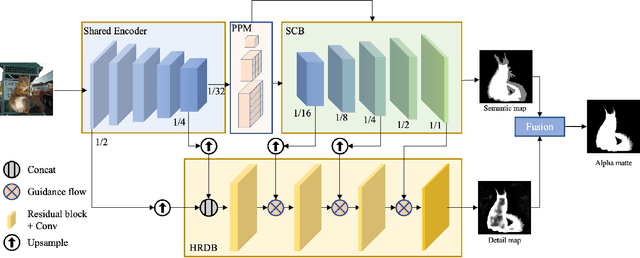
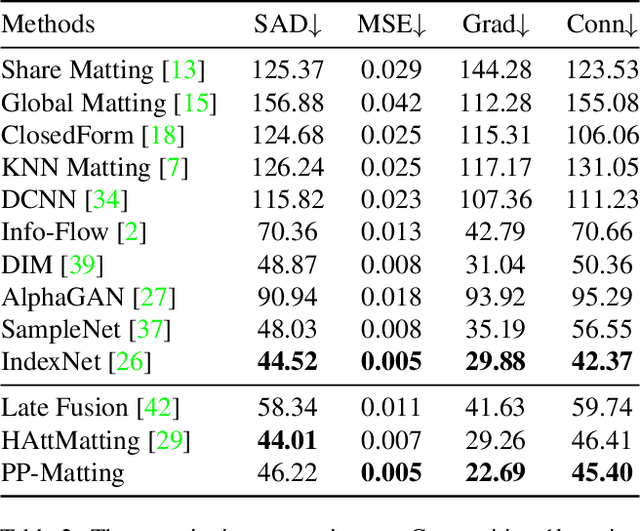
Natural image matting is a fundamental and challenging computer vision task. It has many applications in image editing and composition. Recently, deep learning-based approaches have achieved great improvements in image matting. However, most of them require a user-supplied trimap as an auxiliary input, which limits the matting applications in the real world. Although some trimap-free approaches have been proposed, the matting quality is still unsatisfactory compared to trimap-based ones. Without the trimap guidance, the matting models suffer from foreground-background ambiguity easily, and also generate blurry details in the transition area. In this work, we propose PP-Matting, a trimap-free architecture that can achieve high-accuracy natural image matting. Our method applies a high-resolution detail branch (HRDB) that extracts fine-grained details of the foreground with keeping feature resolution unchanged. Also, we propose a semantic context branch (SCB) that adopts a semantic segmentation subtask. It prevents the detail prediction from local ambiguity caused by semantic context missing. In addition, we conduct extensive experiments on two well-known benchmarks: Composition-1k and Distinctions-646. The results demonstrate the superiority of PP-Matting over previous methods. Furthermore, we provide a qualitative evaluation of our method on human matting which shows its outstanding performance in the practical application. The code and pre-trained models will be available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.