 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion of Self-supervised Learned Models for MOS Prediction
Paper and Code
Apr 11, 2022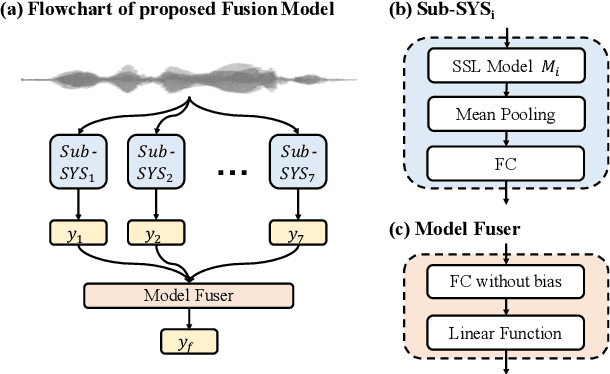
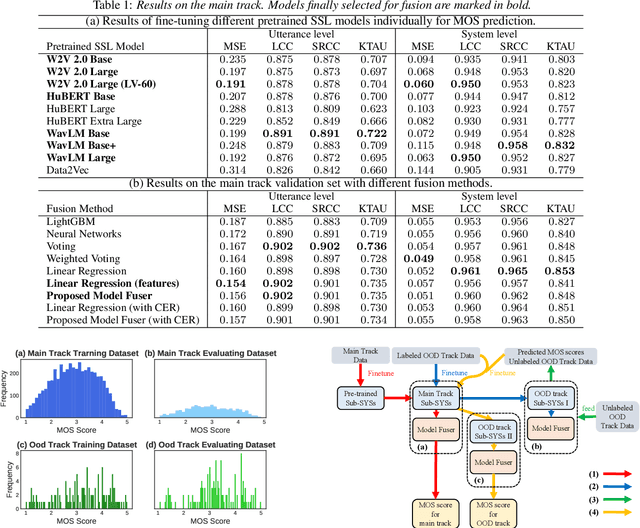
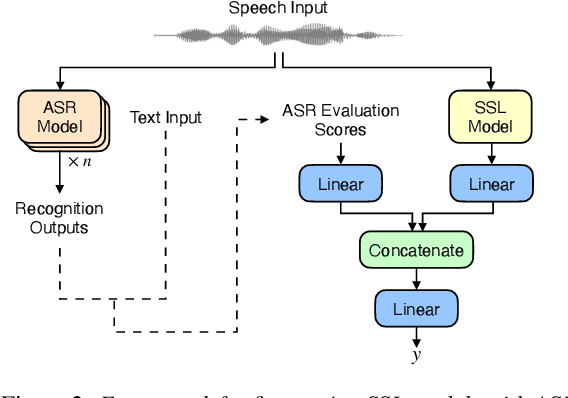
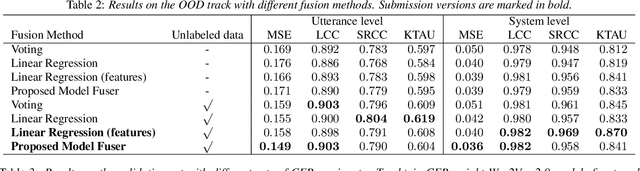
We participated in the mean opinion score (MOS) prediction challenge, 2022. This challenge aims to predict MOS scores of synthetic speech on two tracks, the main track and a more challenging sub-track: out-of-domain (OOD). To improve the accuracy of the predicted scores, we have explored several model fusion-related strategies and proposed a fused framework in which seven pretrained self-supervised learned (SSL) models have been engaged. These pretrained SSL models are derived from three ASR frameworks, including Wav2Vec, Hubert, and WavLM. For the OOD track, we followed the 7 SSL models selected on the main track and adopted a semi-supervised learning method to exploit the unlabeled data. According to the official analysis results, our system has achieved 1st rank in 6 out of 16 metrics and is one of the top 3 systems for 13 out of 16 metrics. Specifically, we have achieved the highest LCC, SRCC, and KTAU scores at the system level on main track, as well as the best performance on the LCC, SRCC, and KTAU evaluation metrics at the utterance level on OOD track. Compared with the basic SSL models, the prediction accuracy of the fused system has been largely improved, especially on OOD sub-track.