 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Vocoder is All You Need for Speech Super-resolution
Paper and Code
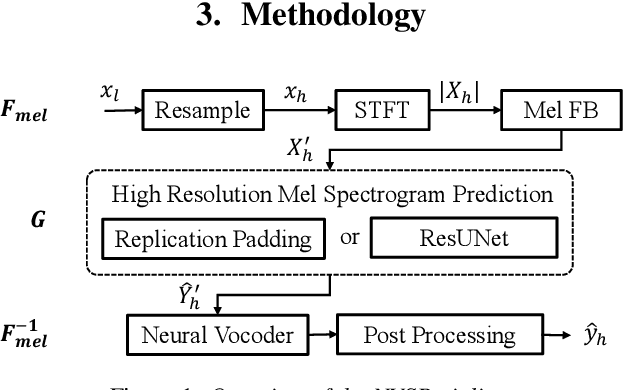

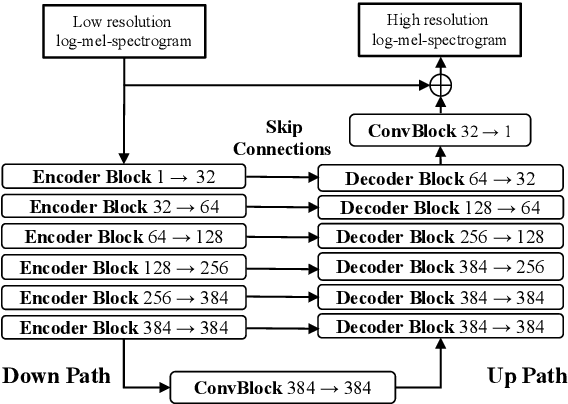

Speech super-resolution (SR) is a task to increase speech sampling rate by generating high-frequency components. Existing speech SR methods are trained in constrained experimental settings, such as a fixed upsampling ratio. These strong constraints can potentially lead to poor generalization ability in mismatched real-world cases. In this paper, we propose a neural vocoder based speech super-resolution method (NVSR) that can handle a variety of input resolution and upsampling ratios. NVSR consists of a mel-bandwidth extension module, a neural vocoder module, and a post-processing module. Our proposed system achieves state-of-the-art results on the VCTK multi-speaker benchmark. On 44.1 kHz target resolution, NVSR outperforms WSRGlow and Nu-wave by 8% and 37% respectively on log spectral distance and achieves a significantly better perceptual quality. We also demonstrate that prior knowledge in the pre-trained vocoder is crucial for speech SR by performing mel-bandwidth extension with a simple replication-padding method. Samples can be found in https://haoheliu.github.io/nvsr.