 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Consistent Semi-supervised Segmentation for 3D Medical Images
Paper and Code
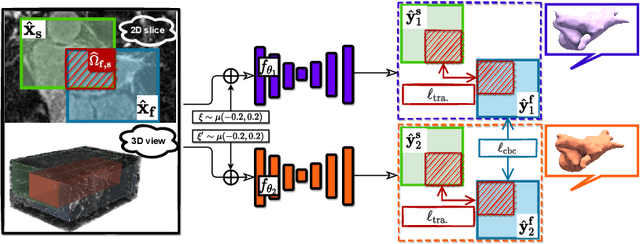
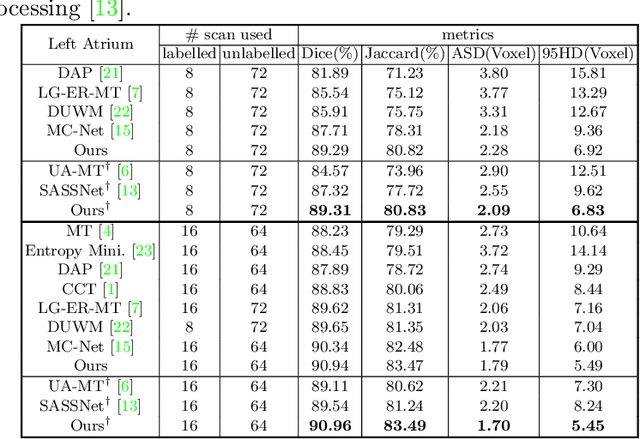
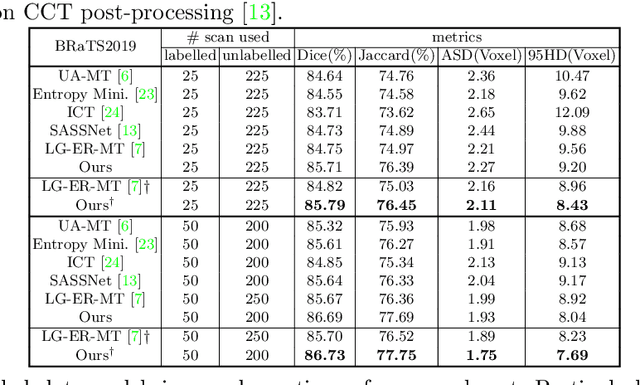
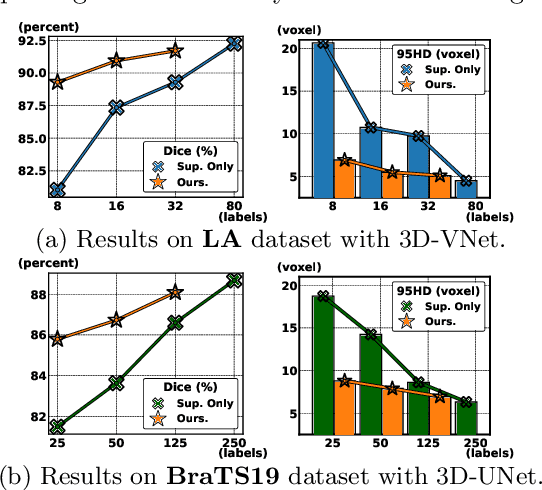
3D medical image segmentation methods have been successful, but their dependence on large amounts of voxel-level annotated data is a disadvantage that needs to be addressed given the high cost to obtain such annotation. Semi-supervised learning (SSL) solve this issue by training models with a large unlabelled and a small labelled dataset. The most successful SSL approaches are based on consistency learning that minimises the distance between model responses obtained from perturbed views of the unlabelled data. These perturbations usually keep the spatial input context between views fairly consistent, which may cause the model to learn segmentation patterns from the spatial input contexts instead of the segmented objects. In this paper, we introduce the Translation Consistent Co-training (TraCoCo) which is a consistency learning SSL method that perturbs the input data views by varying their spatial input context, allowing the model to learn segmentation patterns from visual objects. Furthermore, we propose the replacement of the commonly used mean squared error (MSE) semi-supervised loss by a new Cross-model confident Binary Cross entropy (CBC) loss, which improves training convergence and keeps the robustness to co-training pseudo-labelling mistakes. We also extend CutMix augmentation to 3D SSL to further improve generalisation. Our TraCoCo shows state-of-the-art results for the Left Atrium (LA) and Brain Tumor Segmentation (BRaTS19) datasets with different backbones. Our code is available at https://github.com/yyliu01/TraCoCo.