 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Meet Visual Learning Understanding: A Comprehensive Review
Paper and Code
Mar 24, 2022
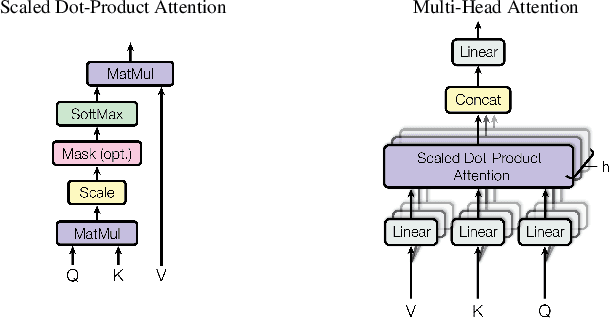
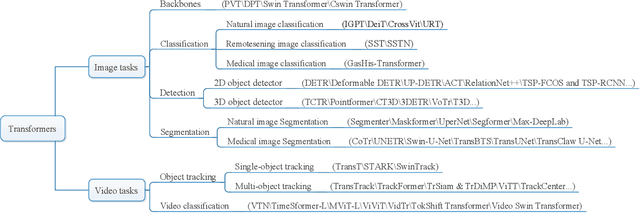
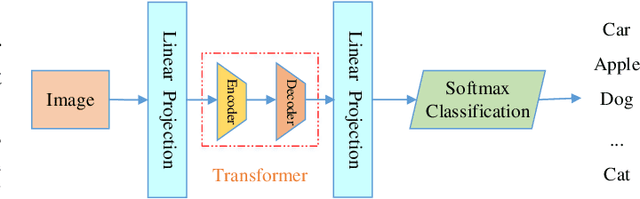
Dynamic attention mechanism and global modeling ability make Transformer show strong feature learning ability. In recent years, Transformer has become comparable to CNNs methods in computer vision. This review mainly investigates the current research progress of Transformer in image and video applications, which makes a comprehensive overview of Transformer in visual learning understanding. First, the attention mechanism is reviewed, which plays an essential part in Transformer. And then, the visual Transformer model and the principle of each module are introduced. Thirdly, the existing Transformer-based models are investigated, and their performance is compared in visual learning understanding applications. Three image tasks and two video tasks of computer vision are investigated. The former mainly includes image classification, object detection, and image segmentation. The latter contains object tracking and video classification. It is significant for comparing different models' performance in various tasks on several public benchmark data sets. Finally, ten general problems are summarized, and the developing prospects of the visual Transformer are given in this review.