 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Representative Keywords Selection: A Probabilistic Approach
Paper and Code

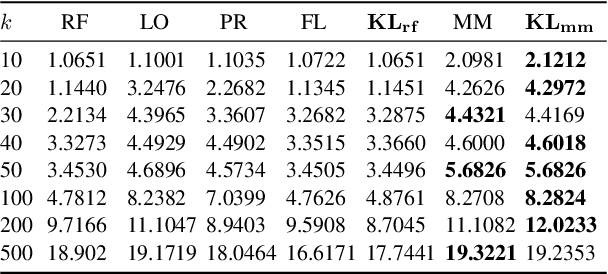
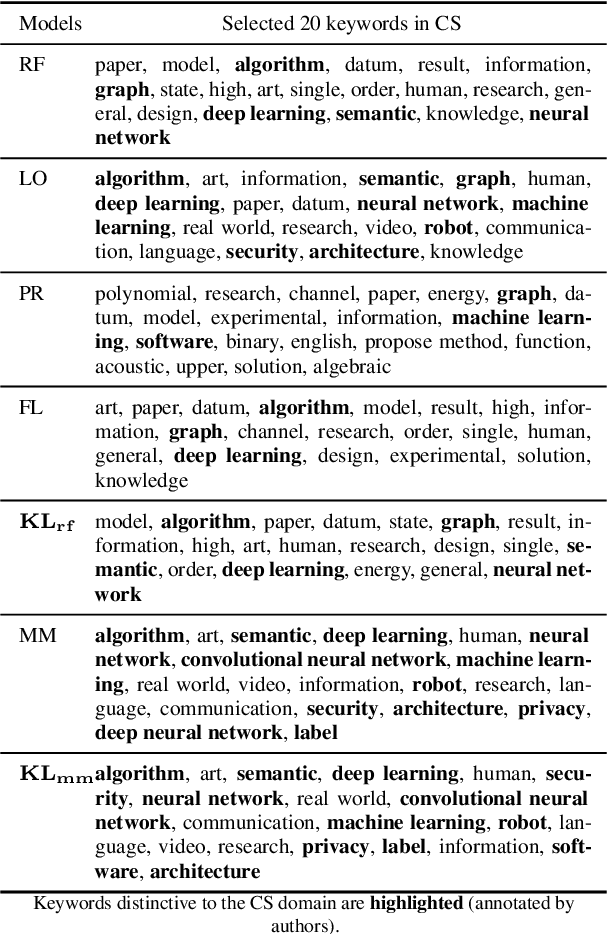
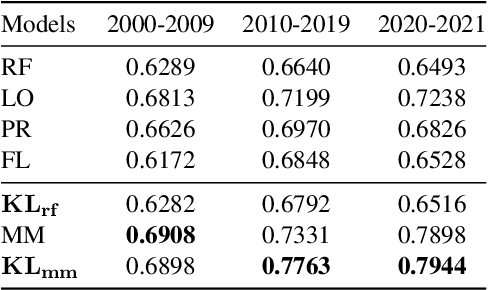
We propose a probabilistic approach to select a subset of a \textit{target domain representative keywords} from a candidate set, contrasting with a context domain. Such a task is crucial for many downstream tasks in natural language processing. To contrast the target domain and the context domain, we adapt the \textit{two-component mixture model} concept to generate a distribution of candidate keywords. It provides more importance to the \textit{distinctive} keywords of the target domain than common keywords contrasting with the context domain. To support the \textit{representativeness} of the selected keywords towards the target domain, we introduce an \textit{optimization algorithm} for selecting the subset from the generated candidate distribution. We have shown that the optimization algorithm can be efficiently implemented with a near-optimal approximation guarantee. Finally, extensive experiments on multiple domains demonstrate the superiority of our approach over other baselines for the tasks of keyword summary generation and trending keywords selection.