 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicNLG Suite: Multilingual Datasets for Diverse NLG Tasks in Indic Languages
Paper and Code
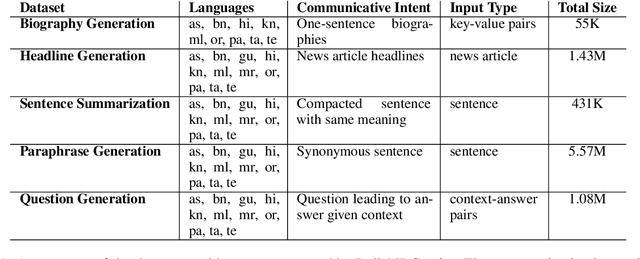
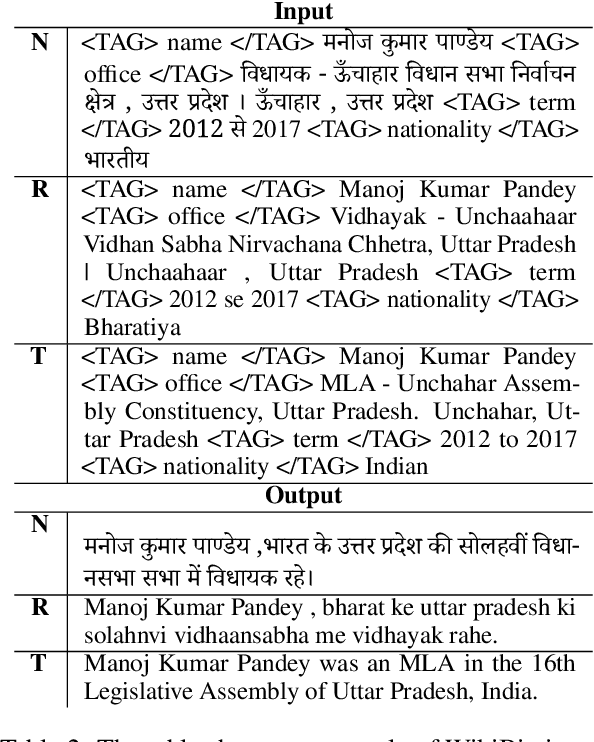
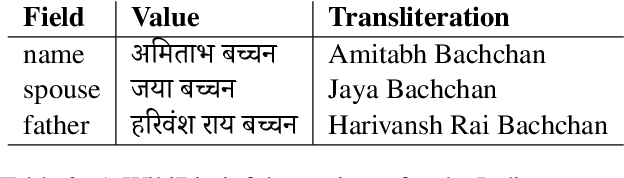
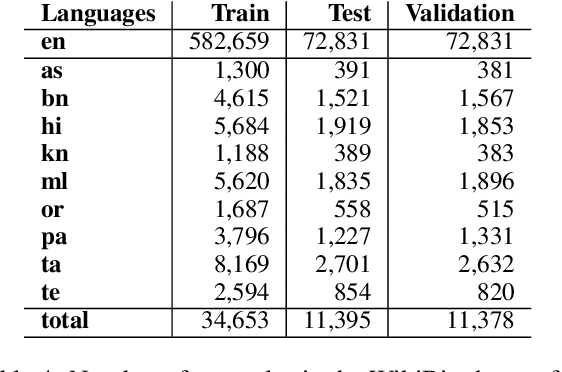
In this paper, we present the IndicNLG suite, a collection of datasets for benchmarking Natural Language Generation (NLG) for 11 Indic languages. We focus on five diverse tasks, namely, biography generation using Wikipedia infoboxes (WikiBio), news headline generation, sentence summarization, question generation and paraphrase generation. We describe the process of creating the datasets and present statistics of the dataset, following which we train and report a variety of strong monolingual and multilingual baselines that leverage pre-trained sequence-to-sequence models and analyze the results to understand the challenges involved in Indic language NLG. To the best of our knowledge, this is the first NLG dataset for Indic languages and also the largest multilingual NLG dataset. Our methods can also be easily applied to modest-resource languages with reasonable monolingual and parallel corpora, as well as corpora containing structured data like Wikipedia. We hope this dataset spurs research in NLG on diverse languages and tasks, particularly for Indic languages. The datasets and models are publicly available at https://indicnlp.ai4bharat.org/indicnlg-suite.