 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual speech separation based on joint feature representation with cross-modal attention
Paper and Code
Mar 05, 2022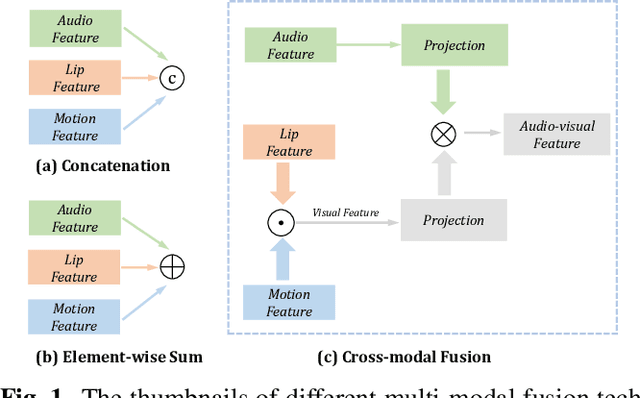
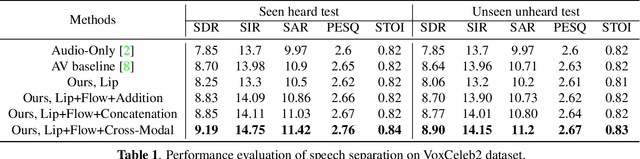
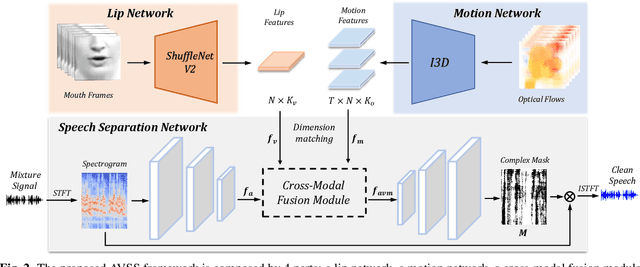
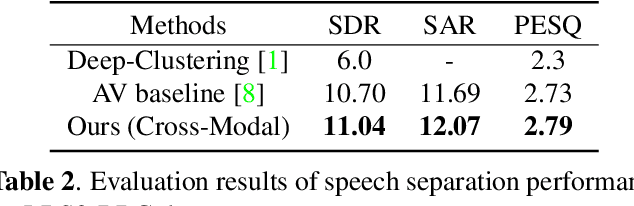
Multi-modal based speech separation has exhibited a specific advantage on isolating the target character in multi-talker noisy environments. Unfortunately, most of current separation strategies prefer a straightforward fusion based on feature learning of each single modality, which is far from sufficient consideration of inter-relationships between modalites. Inspired by learning joint feature representations from audio and visual streams with attention mechanism, in this study, a novel cross-modal fusion strategy is proposed to benefit the whole framework with semantic correlations between different modalities. To further improve audio-visual speech separation, the dense optical flow of lip motion is incorporated to strengthen the robustness of visual representation. The evaluation of the proposed work is performed on two public audio-visual speech separation benchmark datasets. The overall improvement of the performance has demonstrated that the additional motion network effectively enhances the visual representation of the combined lip images and audio signal, as well as outperforming the baseline in terms of all metrics with the proposed cross-modal fusion.