 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoder with Disentanglement Priors for Low-Resource Task-Specific Natural Language Generation
Paper and Code
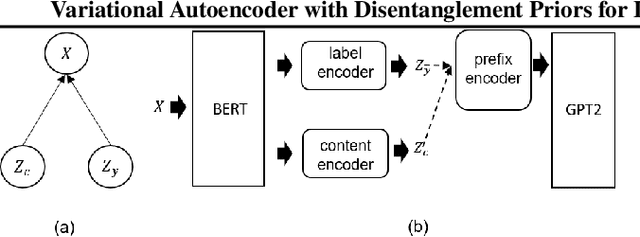
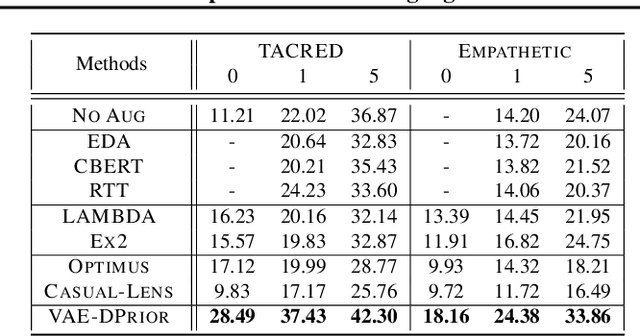
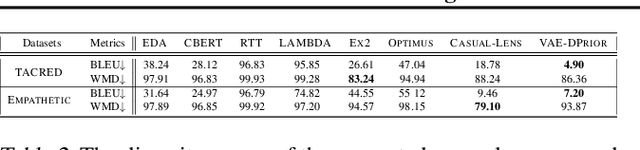
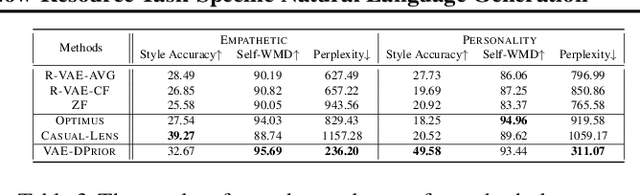
In this paper, we propose a variational autoencoder with disentanglement priors, VAE-DPRIOR, for conditional natural language generation with none or a handful of task-specific labeled examples. In order to improve compositional generalization, our model performs disentangled representation learning by introducing a prior for the latent content space and another prior for the latent label space. We show both empirically and theoretically that the conditional priors can already disentangle representations even without specific regularizations as in the prior work. We can also sample diverse content representations from the content space without accessing data of the seen tasks, and fuse them with the representations of novel tasks for generating diverse texts in the low-resource settings. Our extensive experiments demonstrate the superior performance of our model over competitive baselines in terms of i) data augmentation in continuous zero/few-shot learning, and ii) text style transfer in both zero/few-shot settings.