 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACRONYM: A Large-Scale Dataset for Multilingual and Multi-Domain Acronym Extraction
Paper and Code
Feb 19, 2022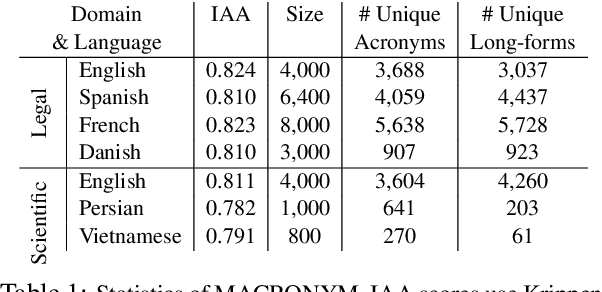
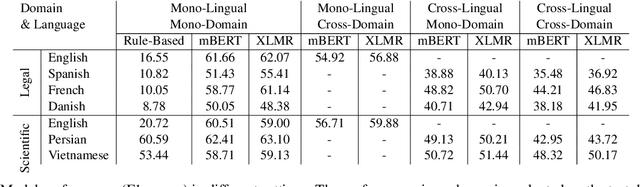
Acronym extraction is the task of identifying acronyms and their expanded forms in texts that is necessary for various NLP applications. Despite major progress for this task in recent years, one limitation of existing AE research is that they are limited to the English language and certain domains (i.e., scientific and biomedical). As such, challenges of AE in other languages and domains is mainly unexplored. Lacking annotated datasets in multiple languages and domains has been a major issue to hinder research in this area. To address this limitation, we propose a new dataset for multilingual multi-domain AE. Specifically, 27,200 sentences in 6 typologically different languages and 2 domains, i.e., Legal and Scientific, is manually annotated for AE. Our extensive experiments on the proposed dataset show that AE in different languages and different learning settings has unique challenges, emphasizing the necessity of further research on multilingual and multi-domain AE.