 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis
Paper and Code

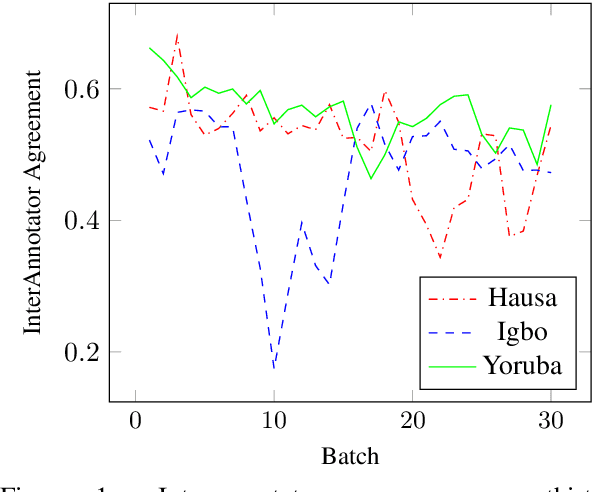

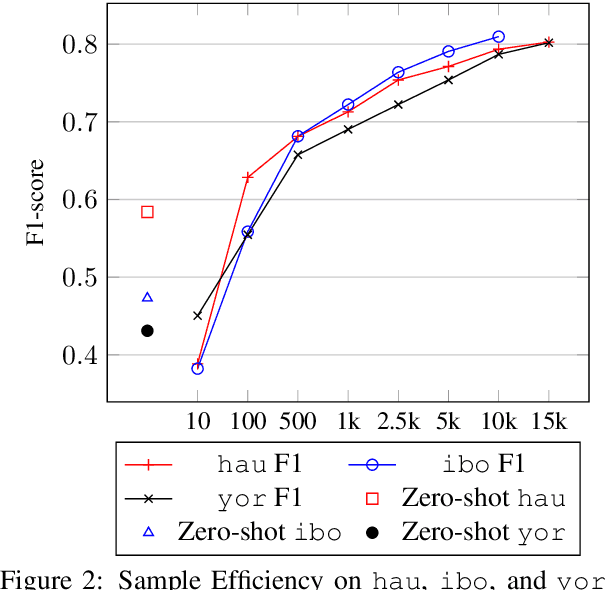
Sentiment analysis is one of the most widely studied applications in NLP, but most work focuses on languages with large amounts of data. We introduce the first large-scale human-annotated Twitter sentiment dataset for the four most widely spoken languages in Nigeria (Hausa, Igbo, Nigerian-Pidgin, and Yor\`ub\'a ) consisting of around 30,000 annotated tweets per language (and 14,000 for Nigerian-Pidgin), including a significant fraction of code-mixed tweets. We propose text collection, filtering, processing and labeling methods that enable us to create datasets for these low-resource languages. We evaluate a rangeof pre-trained models and transfer strategies on the dataset. We find that language-specific models and language-adaptivefine-tuning generally perform best. We release the datasets, trained models, sentiment lexicons, and code to incentivizeresearch on sentiment analysis in under-represented languages.