 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
Paper and Code
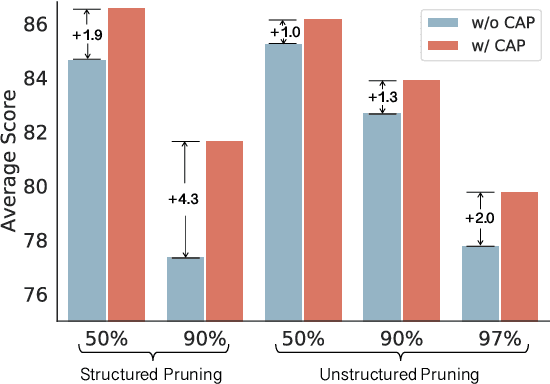
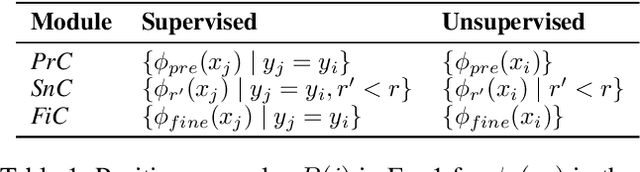
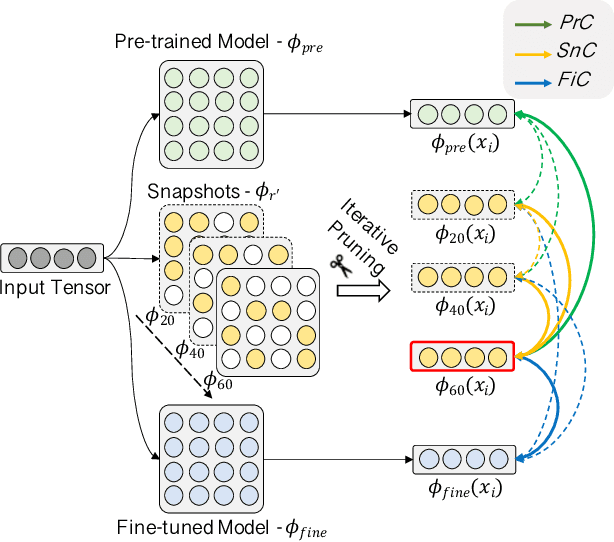
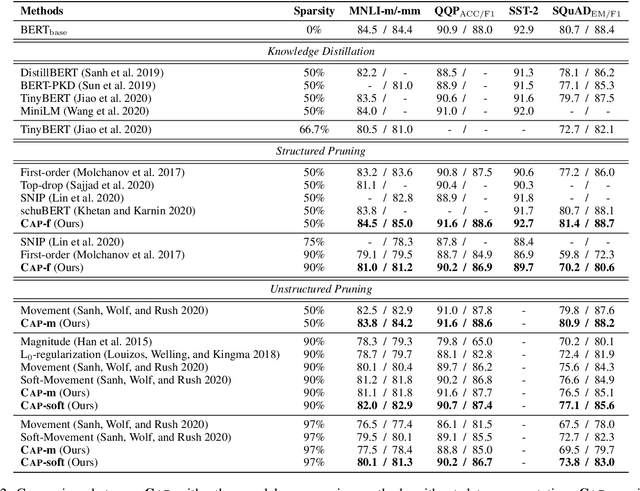
Pre-trained Language Models (PLMs) have achieved great success in various Natural Language Processing (NLP) tasks under the pre-training and fine-tuning paradigm. With large quantities of parameters, PLMs are computation-intensive and resource-hungry. Hence, model pruning has been introduced to compress large-scale PLMs. However, most prior approaches only consider task-specific knowledge towards downstream tasks, but ignore the essential task-agnostic knowledge during pruning, which may cause catastrophic forgetting problem and lead to poor generalization ability. To maintain both task-agnostic and task-specific knowledge in our pruned model, we propose ContrAstive Pruning (CAP) under the paradigm of pre-training and fine-tuning. It is designed as a general framework, compatible with both structured and unstructured pruning. Unified in contrastive learning, CAP enables the pruned model to learn from the pre-trained model for task-agnostic knowledge, and fine-tuned model for task-specific knowledge. Besides, to better retain the performance of the pruned model, the snapshots (i.e., the intermediate models at each pruning iteration) also serve as effective supervisions for pruning. Our extensive experiments show that adopting CAP consistently yields significant improvements, especially in extremely high sparsity scenarios. With only 3% model parameters reserved (i.e., 97% sparsity), CAP successfully achieves 99.2% and 96.3% of the original BERT performance in QQP and MNLI tasks. In addition, our probing experiments demonstrate that the model pruned by CAP tends to achieve better generalization ability.