 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Token Normalization Improves Vision Transformer
Paper and Code
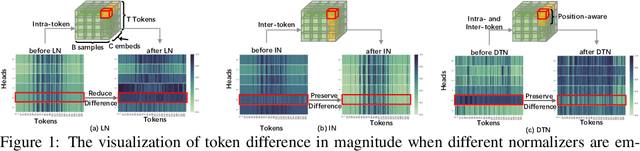
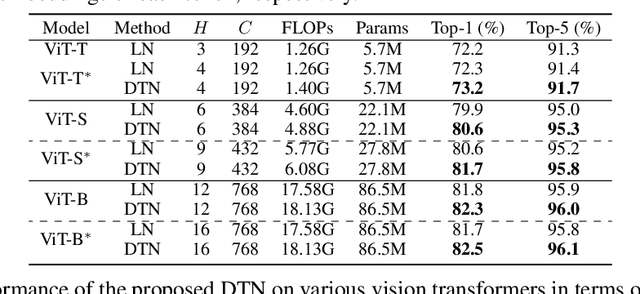
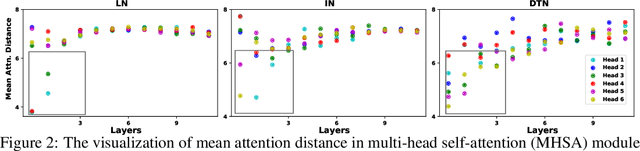

Vision Transformer (ViT) and its variants (e.g., Swin, PVT) have achieved great success in various computer vision tasks, owing to their capability to learn long-range contextual information. Layer Normalization (LN) is an essential ingredient in these models. However, we found that the ordinary LN makes tokens at different positions similar in magnitude because it normalizes embeddings within each token. It is difficult for Transformers to capture inductive bias such as the positional context in an image with LN. We tackle this problem by proposing a new normalizer, termed Dynamic Token Normalization (DTN), where normalization is performed both within each token (intra-token) and across different tokens (inter-token). DTN has several merits. Firstly, it is built on a unified formulation and thus can represent various existing normalization methods. Secondly, DTN learns to normalize tokens in both intra-token and inter-token manners, enabling Transformers to capture both the global contextual information and the local positional context. {Thirdly, by simply replacing LN layers, DTN can be readily plugged into various vision transformers, such as ViT, Swin, PVT, LeViT, T2T-ViT, BigBird and Reformer. Extensive experiments show that the transformer equipped with DTN consistently outperforms baseline model with minimal extra parameters and computational overhead. For example, DTN outperforms LN by $0.5\%$ - $1.2\%$ top-1 accuracy on ImageNet, by $1.2$ - $1.4$ box AP in object detection on COCO benchmark, by $2.3\%$ - $3.9\%$ mCE in robustness experiments on ImageNet-C, and by $0.5\%$ - $0.8\%$ accuracy in Long ListOps on Long-Range Arena.} Codes will be made public at \url{https://github.com/wqshao126/DTN}