 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open Vocabulary Object Detection without Human-provided Bounding Boxes
Paper and Code
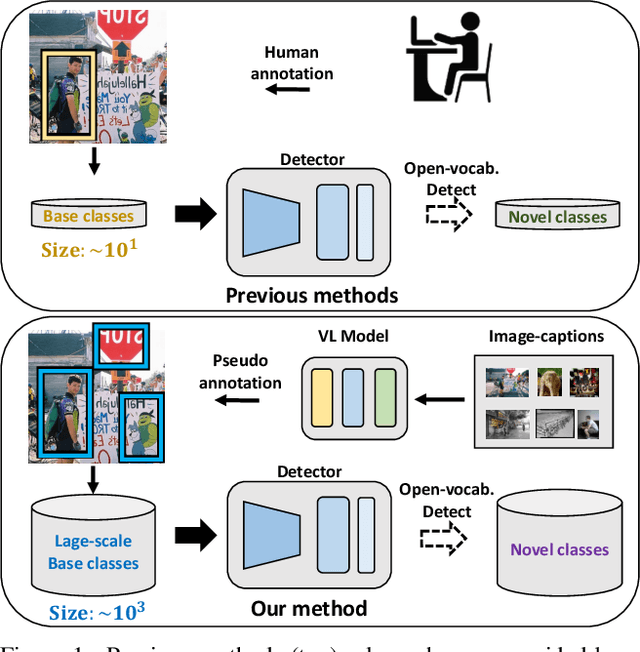
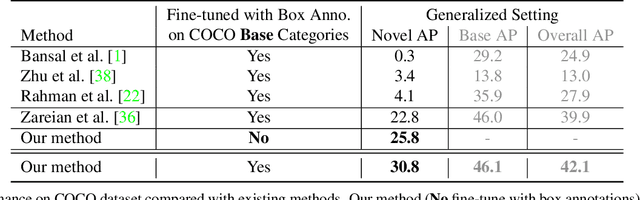
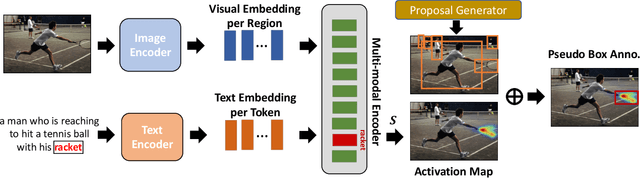
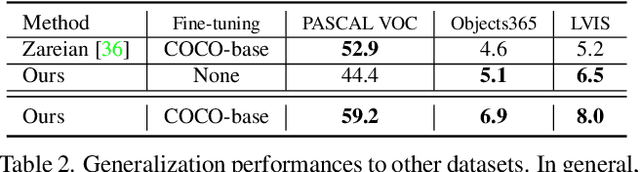
Despite great progress in object detection, most existing methods are limited to a small set of object categories, due to the tremendous human effort needed for instance-level bounding-box annotation. To alleviate the problem, recent open vocabulary and zero-shot detection methods attempt to detect object categories not seen during training. However, these approaches still rely on manually provided bounding-box annotations on a set of base classes. We propose an open vocabulary detection framework that can be trained without manually provided bounding-box annotations. Our method achieves this by leveraging the localization ability of pre-trained vision-language models and generating pseudo bounding-box labels that can be used directly for training object detectors. Experimental results on COCO, PASCAL VOC, Objects365 and LVIS demonstrate the effectiveness of our method. Specifically, our method outperforms the state-of-the-arts (SOTA) that are trained using human annotated bounding-boxes by 3% AP on COCO novel categories even though our training source is not equipped with manual bounding-box labels. When utilizing the manual bounding-box labels as our baselines do, our method surpasses the SOTA largely by 8% AP.