 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBraxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineering beyond Reward Maximization
Paper and Code
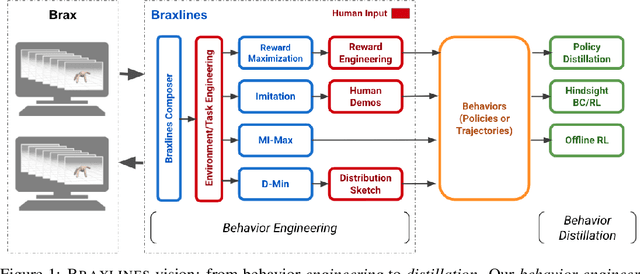



The goal of continuous control is to synthesize desired behaviors. In reinforcement learning (RL)-driven approaches, this is often accomplished through careful task reward engineering for efficient exploration and running an off-the-shelf RL algorithm. While reward maximization is at the core of RL, reward engineering is not the only -- sometimes nor the easiest -- way for specifying complex behaviors. In this paper, we introduce \braxlines, a toolkit for fast and interactive RL-driven behavior generation beyond simple reward maximization that includes Composer, a programmatic API for generating continuous control environments, and set of stable and well-tested baselines for two families of algorithms -- mutual information maximization (MiMax) and divergence minimization (DMin) -- supporting unsupervised skill learning and distribution sketching as other modes of behavior specification. In addition, we discuss how to standardize metrics for evaluating these algorithms, which can no longer rely on simple reward maximization. Our implementations build on a hardware-accelerated Brax simulator in Jax with minimal modifications, enabling behavior synthesis within minutes of training. We hope Braxlines can serve as an interactive toolkit for rapid creation and testing of environments and behaviors, empowering explosions of future benchmark designs and new modes of RL-driven behavior generation and their algorithmic research.