 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Significant Bit Quantization and Acceleration for Deep Neural Networks
Paper and Code
Sep 08, 2021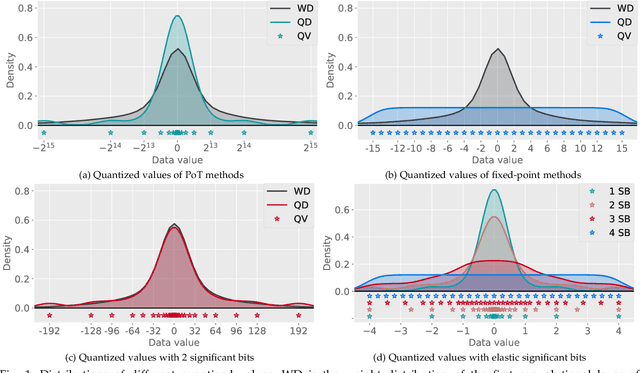
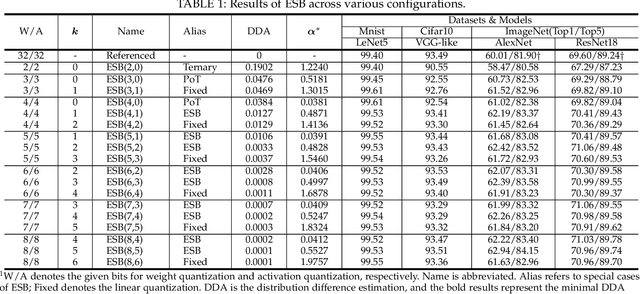
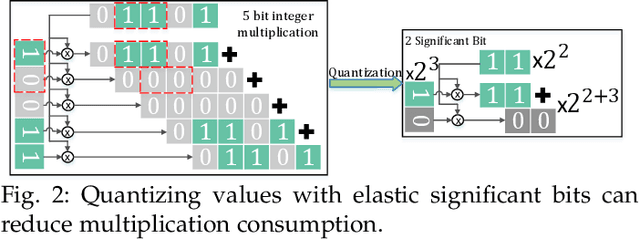
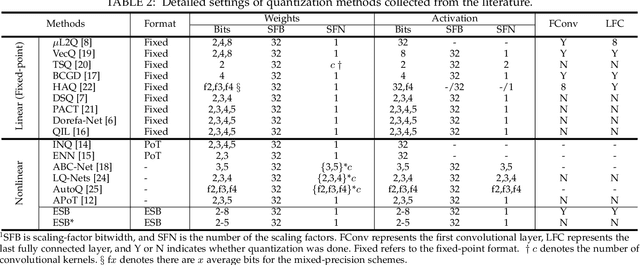
Quantization has been proven to be a vital method for improving the inference efficiency of deep neural networks (DNNs). However, it is still challenging to strike a good balance between accuracy and efficiency while quantizing DNN weights or activation values from high-precision formats to their quantized counterparts. We propose a new method called elastic significant bit quantization (ESB) that controls the number of significant bits of quantized values to obtain better inference accuracy with fewer resources. We design a unified mathematical formula to constrain the quantized values of the ESB with a flexible number of significant bits. We also introduce a distribution difference aligner (DDA) to quantitatively align the distributions between the full-precision weight or activation values and quantized values. Consequently, ESB is suitable for various bell-shaped distributions of weights and activation of DNNs, thus maintaining a high inference accuracy. Benefitting from fewer significant bits of quantized values, ESB can reduce the multiplication complexity. We implement ESB as an accelerator and quantitatively evaluate its efficiency on FPGAs. Extensive experimental results illustrate that ESB quantization consistently outperforms state-of-the-art methods and achieves average accuracy improvements of 4.78%, 1.92%, and 3.56% over AlexNet, ResNet18, and MobileNetV2, respectively. Furthermore, ESB as an accelerator can achieve 10.95 GOPS peak performance of 1k LUTs without DSPs on the Xilinx ZCU102 FPGA platform. Compared with CPU, GPU, and state-of-the-art accelerators on FPGAs, the ESB accelerator can improve the energy efficiency by up to 65x, 11x, and 26x, respectively.