 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
Paper and Code
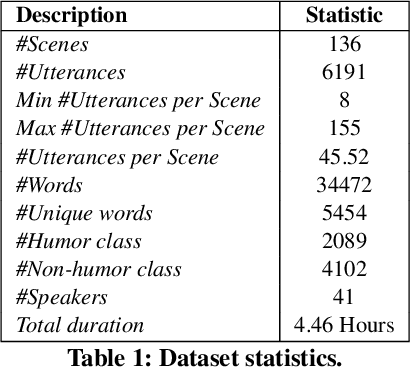

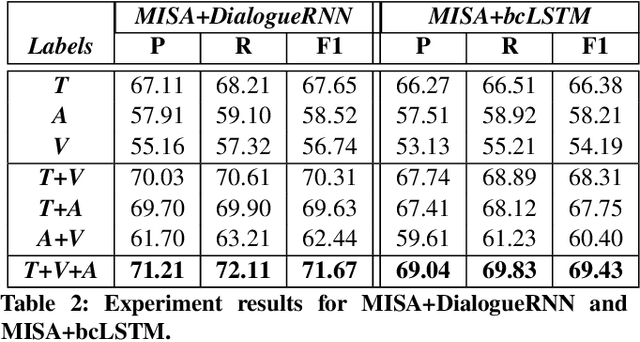

Humor recognition in conversations is a challenging task that has recently gained popularity due to its importance in dialogue understanding, including in multimodal settings (i.e., text, acoustics, and visual). The few existing datasets for humor are mostly in English. However, due to the tremendous growth in multilingual content, there is a great demand to build models and systems that support multilingual information access. To this end, we propose a dataset for Multimodal Multiparty Hindi Humor (M2H2) recognition in conversations containing 6,191 utterances from 13 episodes of a very popular TV series "Shrimaan Shrimati Phir Se". Each utterance is annotated with humor/non-humor labels and encompasses acoustic, visual, and textual modalities. We propose several strong multimodal baselines and show the importance of contextual and multimodal information for humor recognition in conversations. The empirical results on M2H2 dataset demonstrate that multimodal information complements unimodal information for humor recognition. The dataset and the baselines are available at http://www.iitp.ac.in/~ai-nlp-ml/resources.html and https://github.com/declare-lab/M2H2-dataset.