 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2Learn: High-Efficiency Learning Accelerator for High-Accuracy Spiking Neural Networks
Paper and Code
Jul 25, 2021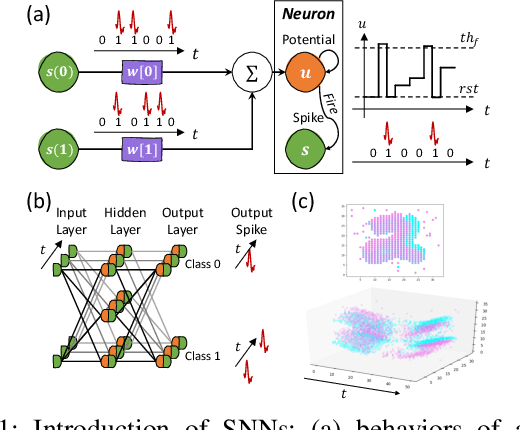
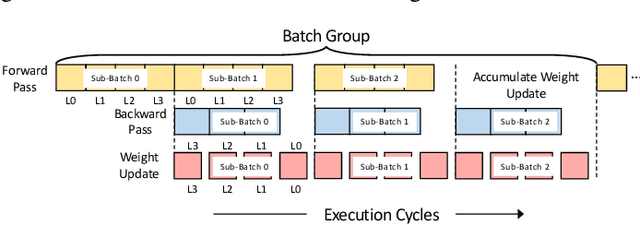
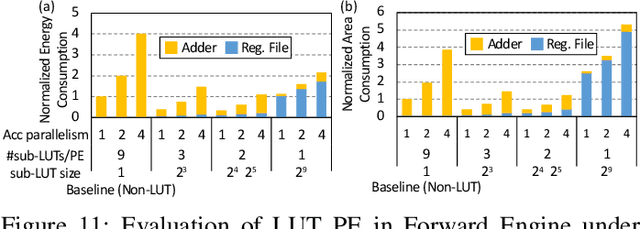
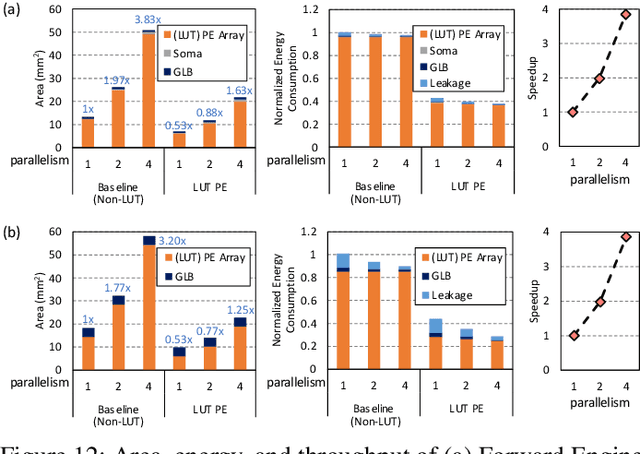
Although spiking neural networks (SNNs) take benefits from the bio-plausible neural modeling, the low accuracy under the common local synaptic plasticity learning rules limits their application in many practical tasks. Recently, an emerging SNN supervised learning algorithm inspired by backpropagation through time (BPTT) from the domain of artificial neural networks (ANNs) has successfully boosted the accuracy of SNNs and helped improve the practicability of SNNs. However, current general-purpose processors suffer from low efficiency when performing BPTT for SNNs due to the ANN-tailored optimization. On the other hand, current neuromorphic chips cannot support BPTT because they mainly adopt local synaptic plasticity rules for simplified implementation. In this work, we propose H2Learn, a novel architecture that can achieve high efficiency for BPTT-based SNN learning which ensures high accuracy of SNNs. At the beginning, we characterized the behaviors of BPTT-based SNN learning. Benefited from the binary spike-based computation in the forward pass and the weight update, we first design lookup table (LUT) based processing elements in Forward Engine and Weight Update Engine to make accumulations implicit and to fuse the computations of multiple input points. Second, benefited from the rich sparsity in the backward pass, we design a dual-sparsity-aware Backward Engine which exploits both input and output sparsity. Finally, we apply a pipeline optimization between different engines to build an end-to-end solution for the BPTT-based SNN learning. Compared with the modern NVIDIA V100 GPU, H2Learn achieves 7.38x area saving, 5.74-10.20x speedup, and 5.25-7.12x energy saving on several benchmark datasets.