 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Adversarial Attacks on Observations in Deep Reinforcement Learning
Paper and Code
Jun 30, 2021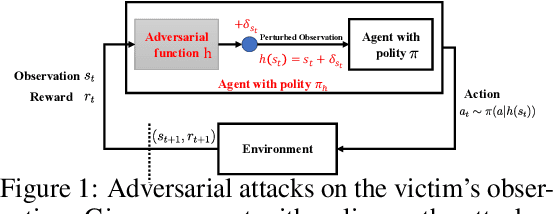
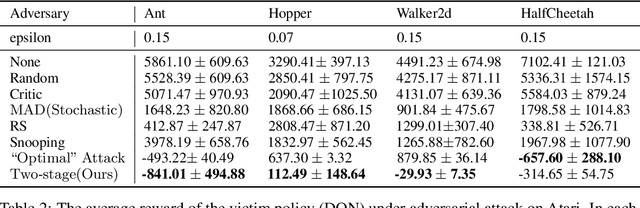
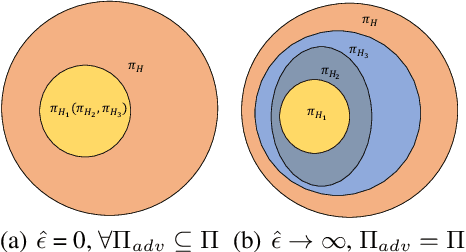
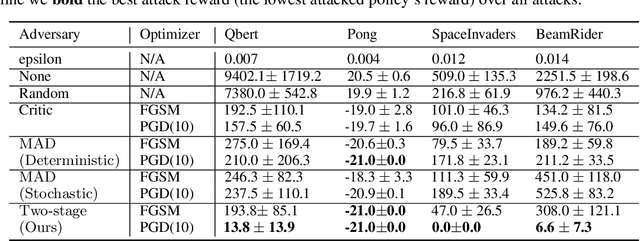
Recent works demonstrate that deep reinforcement learning (DRL) models are vulnerable to adversarial attacks which can decrease the victim's total reward by manipulating the observations. Compared with adversarial attacks in supervised learning, it is much more challenging to deceive a DRL model since the adversary has to infer the environmental dynamics. To address this issue, we reformulate the problem of adversarial attacks in function space and separate the previous gradient based attacks into several subspace. Following the analysis of the function space, we design a generic two-stage framework in the subspace where the adversary lures the agent to a target trajectory or a deceptive policy. In the first stage, we train a deceptive policy by hacking the environment, and discover a set of trajectories routing to the lowest reward. The adversary then misleads the victim to imitate the deceptive policy by perturbing the observations. Our method provides a tighter theoretical upper bound for the attacked agent's performance than the existing approaches. Extensive experiments demonstrate the superiority of our method and we achieve the state-of-the-art performance on both Atari and MuJoCo environments.