 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Speaker ASR Combining Non-Autoregressive Conformer CTC and Conditional Speaker Chain
Paper and Code
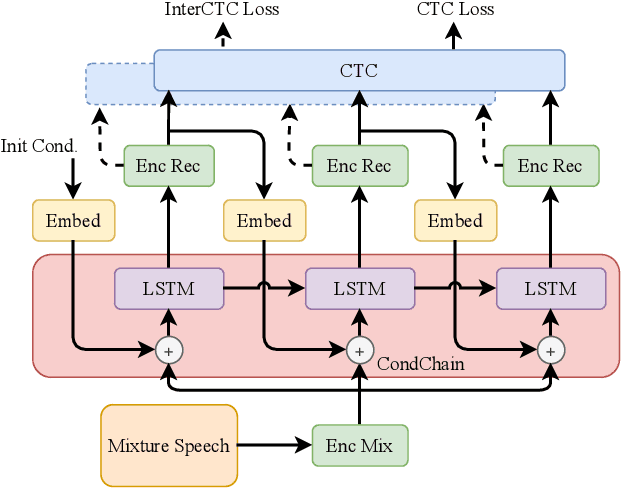



Non-autoregressive (NAR) models have achieved a large inference computation reduction and comparable results with autoregressive (AR) models on various sequence to sequence tasks. However, there has been limited research aiming to explore the NAR approaches on sequence to multi-sequence problems, like multi-speaker automatic speech recognition (ASR). In this study, we extend our proposed conditional chain model to NAR multi-speaker ASR. Specifically, the output of each speaker is inferred one-by-one using both the input mixture speech and previously-estimated conditional speaker features. In each step, a NAR connectionist temporal classification (CTC) encoder is used to perform parallel computation. With this design, the total inference steps will be restricted to the number of mixed speakers. Besides, we also adopt the Conformer and incorporate an intermediate CTC loss to improve the performance. Experiments on WSJ0-Mix and LibriMix corpora show that our model outperforms other NAR models with only a slight increase of latency, achieving WERs of 22.3% and 24.9%, respectively. Moreover, by including the data of variable numbers of speakers, our model can even better than the PIT-Conformer AR model with only 1/7 latency, obtaining WERs of 19.9% and 34.3% on WSJ0-2mix and WSJ0-3mix sets. All of our codes are publicly available at https://github.com/pengchengguo/espnet/tree/conditional-multispk.