 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBertGCN: Transductive Text Classification by Combining GCN and BERT
Paper and Code
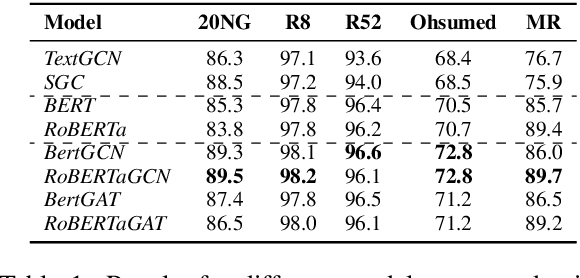

In this work, we propose BertGCN, a model that combines large scale pretraining and transductive learning for text classification. BertGCN constructs a heterogeneous graph over the dataset and represents documents as nodes using BERT representations. By jointly training the BERT and GCN modules within BertGCN, the proposed model is able to leverage the advantages of both worlds: large-scale pretraining which takes the advantage of the massive amount of raw data and transductive learning which jointly learns representations for both training data and unlabeled test data by propagating label influence through graph convolution. Experiments show that BertGCN achieves SOTA performances on a wide range of text classification datasets. Code is available at https://github.com/ZeroRin/BertGCN.