 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentLaM: Decentralized Momentum SGD for Large-batch Deep Training
Paper and Code
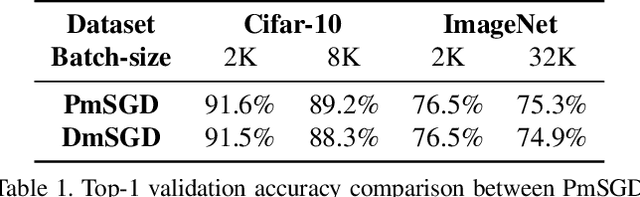
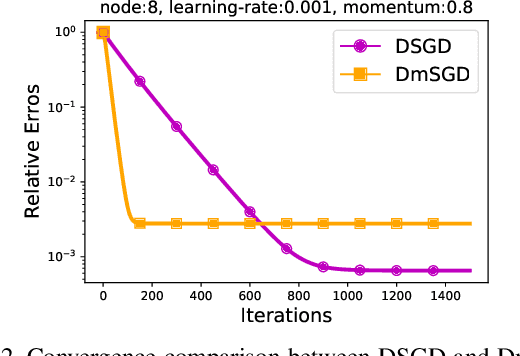
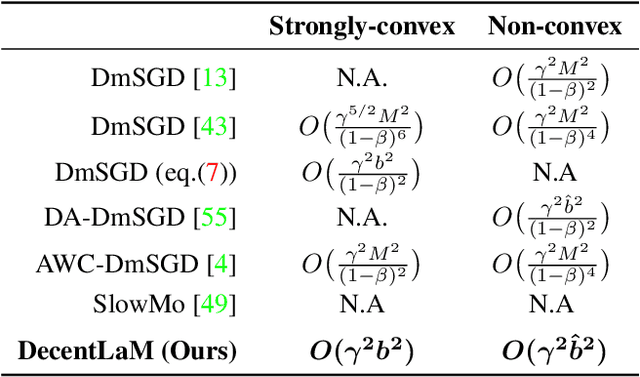
The scale of deep learning nowadays calls for efficient distributed training algorithms. Decentralized momentum SGD (DmSGD), in which each node averages only with its neighbors, is more communication efficient than vanilla Parallel momentum SGD that incurs global average across all computing nodes. On the other hand, the large-batch training has been demonstrated critical to achieve runtime speedup. This motivates us to investigate how DmSGD performs in the large-batch scenario. In this work, we find the momentum term can amplify the inconsistency bias in DmSGD. Such bias becomes more evident as batch-size grows large and hence results in severe performance degradation. We next propose DecentLaM, a novel decentralized large-batch momentum SGD to remove the momentum-incurred bias. The convergence rate for both non-convex and strongly-convex scenarios is established. Our theoretical results justify the superiority of DecentLaM to DmSGD especially in the large-batch scenario. Experimental results on a variety of computer vision tasks and models demonstrate that DecentLaM promises both efficient and high-quality training.