 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Subsets Knowledge Distillation for Long-tailed Retinal Diseases Recognition
Paper and Code
Apr 22, 2021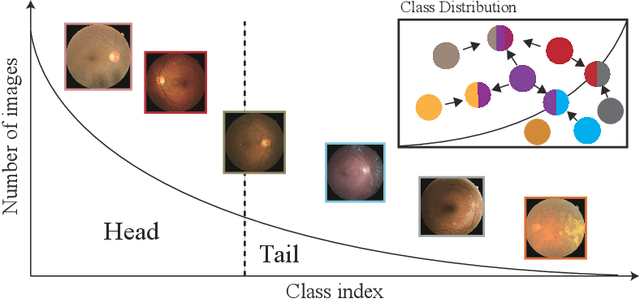

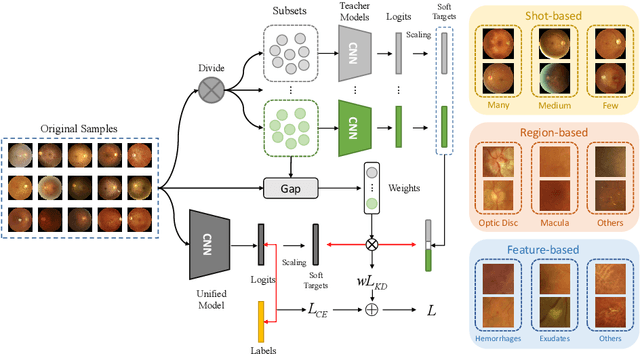
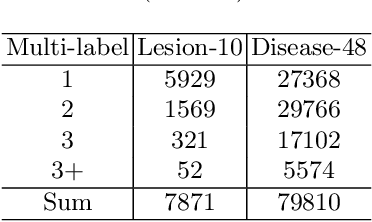
In the real world, medical datasets often exhibit a long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples), which results in a challenging imbalance learning scenario. For example, there are estimated more than 40 different kinds of retinal diseases with variable morbidity, however with more than 30+ conditions are very rare from the global patient cohorts, which results in a typical long-tailed learning problem for deep learning-based screening models. In this study, we propose class subset learning by dividing the long-tailed data into multiple class subsets according to prior knowledge, such as regions and phenotype information. It enforces the model to focus on learning the subset-specific knowledge. More specifically, there are some relational classes that reside in the fixed retinal regions, or some common pathological features are observed in both the majority and minority conditions. With those subsets learnt teacher models, then we are able to distill the multiple teacher models into a unified model with weighted knowledge distillation loss. The proposed framework proved to be effective for the long-tailed retinal diseases recognition task. The experimental results on two different datasets demonstrate that our method is flexible and can be easily plugged into many other state-of-the-art techniques with significant improvements.