 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleFreeCTR: MixCache-based Distributed Training System for CTR Models with Huge Embedding Table
Paper and Code
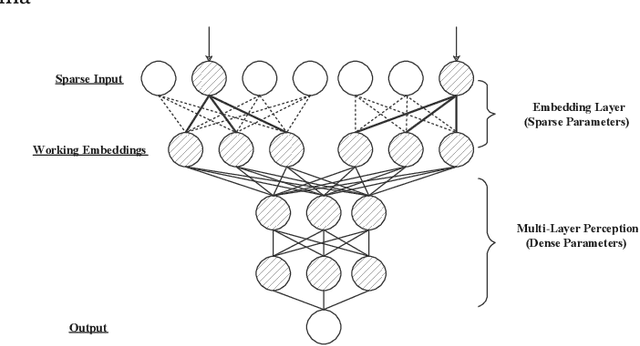

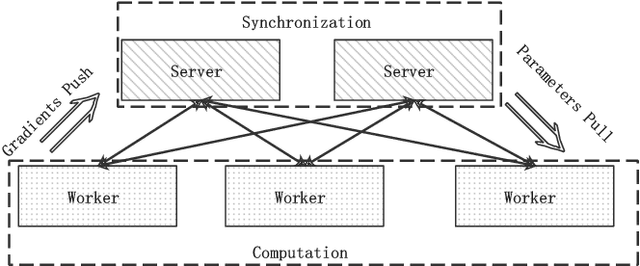
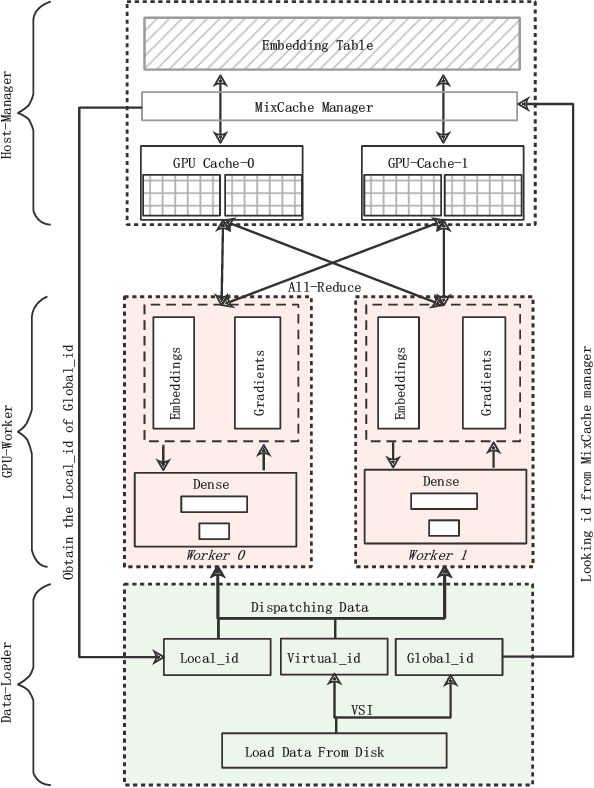
Because of the superior feature representation ability of deep learning, various deep Click-Through Rate (CTR) models are deployed in the commercial systems by industrial companies. To achieve better performance, it is necessary to train the deep CTR models on huge volume of training data efficiently, which makes speeding up the training process an essential problem. Different from the models with dense training data, the training data for CTR models is usually high-dimensional and sparse. To transform the high-dimensional sparse input into low-dimensional dense real-value vectors, almost all deep CTR models adopt the embedding layer, which easily reaches hundreds of GB or even TB. Since a single GPU cannot afford to accommodate all the embedding parameters, when performing distributed training, it is not reasonable to conduct the data-parallelism only. Therefore, existing distributed training platforms for recommendation adopt model-parallelism. Specifically, they use CPU (Host) memory of servers to maintain and update the embedding parameters and utilize GPU worker to conduct forward and backward computations. Unfortunately, these platforms suffer from two bottlenecks: (1) the latency of pull \& push operations between Host and GPU; (2) parameters update and synchronization in the CPU servers. To address such bottlenecks, in this paper, we propose the ScaleFreeCTR: a MixCache-based distributed training system for CTR models. Specifically, in SFCTR, we also store huge embedding table in CPU but utilize GPU instead of CPU to conduct embedding synchronization efficiently. To reduce the latency of data transfer between both GPU-Host and GPU-GPU, the MixCache mechanism and Virtual Sparse Id operation are proposed. Comprehensive experiments and ablation studies are conducted to demonstrate the effectiveness and efficiency of SFCTR.