 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerial or Parallel? Plug-able Adapter for multilingual machine translation
Paper and Code
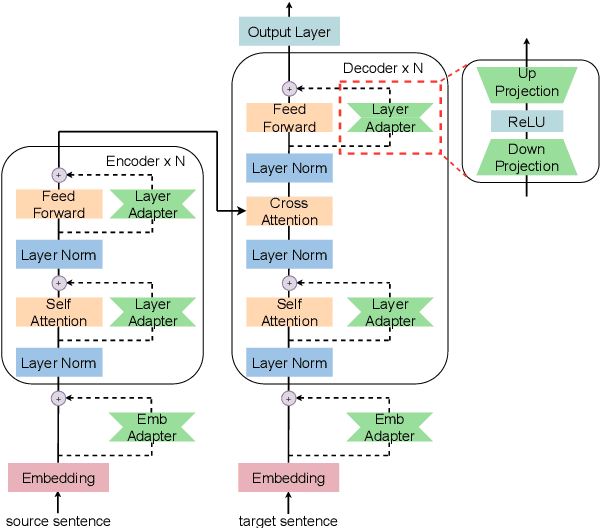

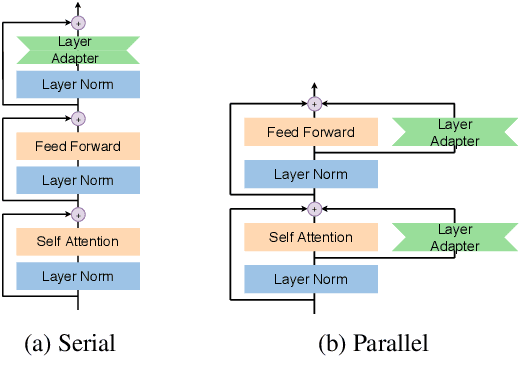
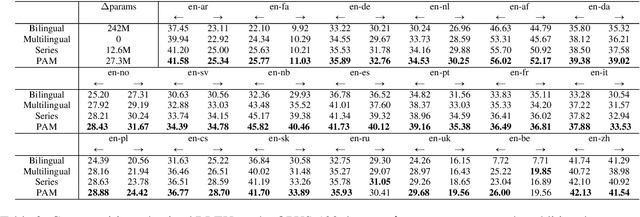
Developing a unified multilingual translation model is a key topic in machine translation research. However, existing approaches suffer from performance degradation: multilingual models yield inferior performance compared to the ones trained separately on rich bilingual data. We attribute the performance degradation to two issues: multilingual embedding conflation and multilingual fusion effects. To address the two issues, we propose PAM, a Transformer model augmented with defusion adaptation for multilingual machine translation. Specifically, PAM consists of embedding and layer adapters to shift the word and intermediate representations towards language-specific ones. Extensive experiment results on IWSLT, OPUS-100, and WMT benchmarks show that \method outperforms several strong competitors, including series adapter and multilingual knowledge distillation.