 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact and Approximate Hierarchical Clustering Using A*
Paper and Code
Apr 14, 2021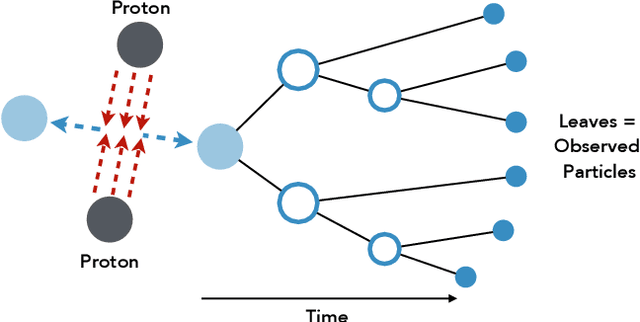
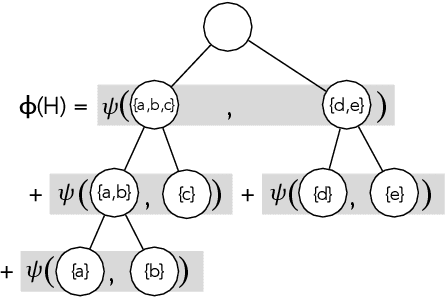
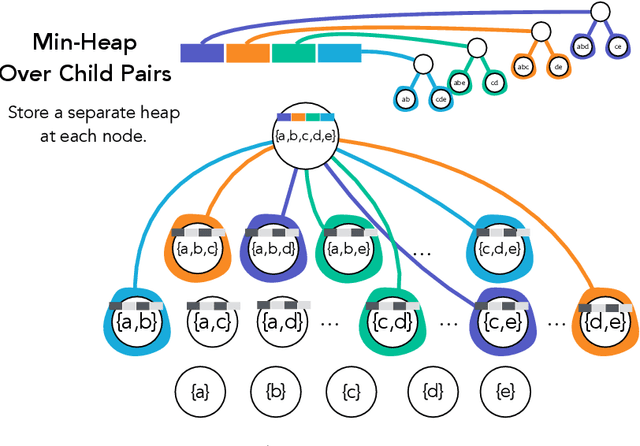
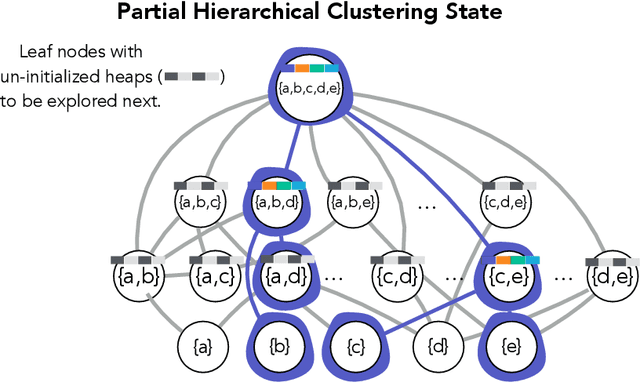
Hierarchical clustering is a critical task in numerous domains. Many approaches are based on heuristics and the properties of the resulting clusterings are studied post hoc. However, in several applications, there is a natural cost function that can be used to characterize the quality of the clustering. In those cases, hierarchical clustering can be seen as a combinatorial optimization problem. To that end, we introduce a new approach based on A* search. We overcome the prohibitively large search space by combining A* with a novel \emph{trellis} data structure. This combination results in an exact algorithm that scales beyond previous state of the art, from a search space with $10^{12}$ trees to $10^{15}$ trees, and an approximate algorithm that improves over baselines, even in enormous search spaces that contain more than $10^{1000}$ trees. We empirically demonstrate that our method achieves substantially higher quality results than baselines for a particle physics use case and other clustering benchmarks. We describe how our method provides significantly improved theoretical bounds on the time and space complexity of A* for clustering.